1. 从知识到代码:AI 辅助研发的知识与工具链组合拳
本文基于我近期使用 AI 辅助研发的实践经验,不空谈概念,只回答一个具体问题:
当团队同时拥有多个基础库、多个业务仓库和大量业务文档时,如何让 AI 不再每次都从零开始读资料、翻代码、猜架构?
我的结论是:要把AI的上下文系统拆成两层:
- Codebase Memory MCP作为事实层(Fact Layer):回答代码里“确实发生了什么”。
- LLM Wiki 作为知识层(Knowledge Layer):沉淀团队对系统“为什么这样设计”的理解。
AI 辅助研发的瓶颈,不是模型会不会聊天,而是它有没有一套可复用、可验证、能持续积累的上下文。代码事实必须可追溯,架构知识必须可解释;二者混在一起,就会变成一团难以校验的“智能摘要”。
1.1. 知识管理:先分清“事实”和“解释”
团队知识主要来自两类材料:
- 文档:Markdown、TXT、Word、PPT、图片、会议纪要、需求说明等。
- 代码:基础库、业务仓库、脚本、配置、API等。
这两类材料解决的问题不同。
文档更接近“人类解释”:它告诉我们业务目标、设计背景、决策过程和历史包袱。代码更接近“机器事实”:它告诉我们真实调用链、真实依赖、真实入口和真实边界。
因此,知识管理的关键不是把所有材料塞进一个向量库,而是让不同类型的知识进入合适的层。
1.2. 文档管理:用 LLM Wiki 沉淀可演进的知识
LLM Wiki 的思路来自 Andrej Karpathy 的 llm-wiki.md。它不是一个具体产品,而是一种知识库模式:让 LLM 读取原始资料,然后持续维护一组结构化、互相链接的 Markdown 页面。
传统 RAG 更像“临时翻书”:每次提问时,系统从原始材料中检索相关片段,再即时拼出答案。它能回答问题,但知识不会自然沉淀。
LLM Wiki 更像“请一个研究助理长期维护笔记”:新资料进入后,LLM 不只是索引它,而是把它整合进已有 wiki,更新主题页、实体页、概览页和综合分析页。矛盾会被标记,旧结论会被修订,知识会越用越厚。
我使用的是 GitHub 上的 nashsu/llm_wiki 客户端。它的定位是跨平台桌面应用:把文档转化为结构化、互相关联、可持续维护的知识库。
它的价值主要体现在三点:
- 把资料变成知识:不是只保存文件,而是提炼出主题、实体、关系和结论。
- 把一次性问答变成长期积累:每次新增材料或追问问题,都可以反向更新wiki。
- 把个人理解变成团队资产:Markdown 文件天然适合版本管理、评审、链接和二次加工。
一个生活化类比是:RAG 像每次开会前临时翻资料,LLM Wiki 像有一个长期维护的项目手册。前者适合快速找答案,后者适合积累组织记忆。
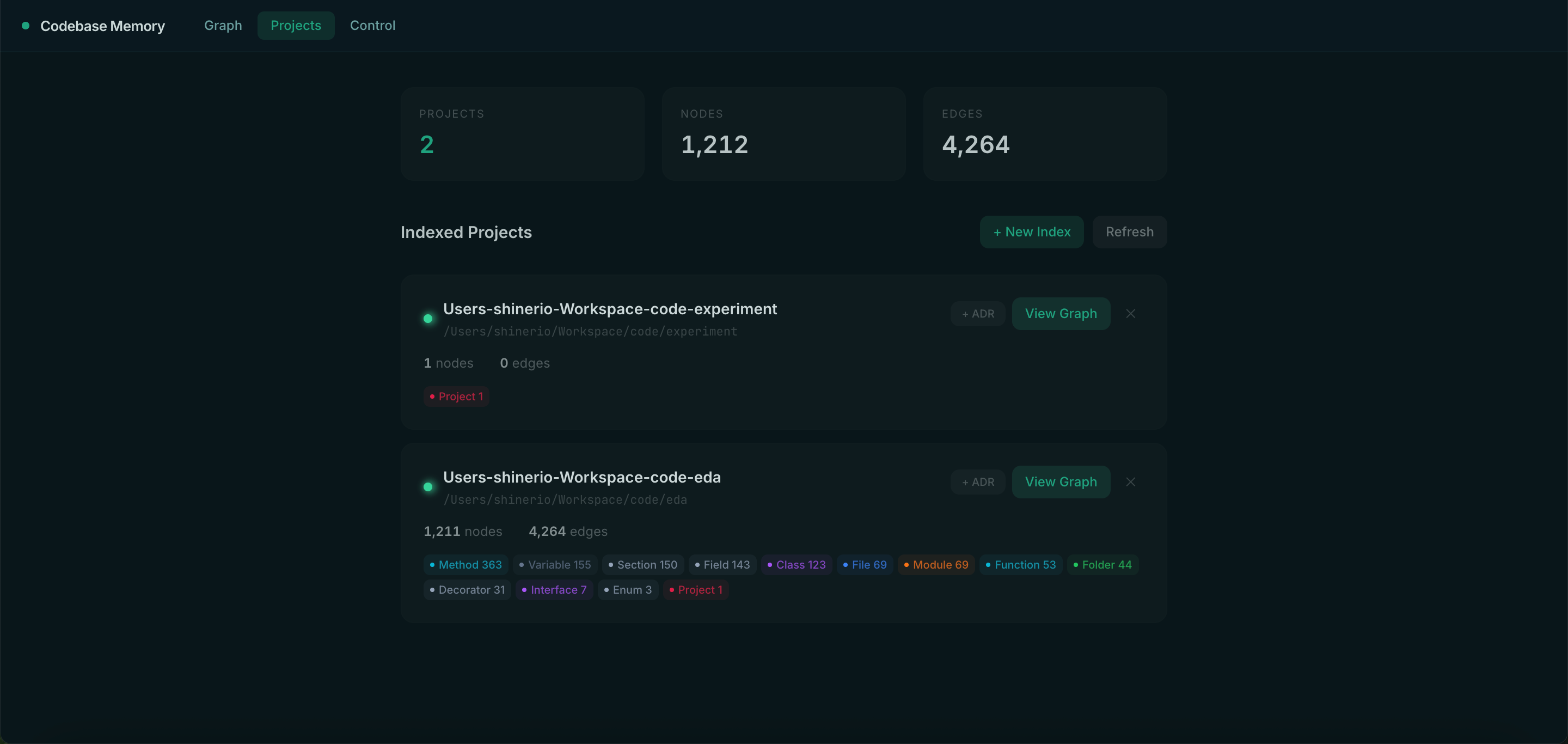
1.3. 代码管理:用 Codebase Memory MCP 建立代码事实层
DeusData/codebase-memory-mcp 是一个面向 AI 编程助手的 MCP Server,可用于 Claude Code、Codex、Cursor 等工具链。
它的核心作用是:预先解析代码库,构建本地持久化的代码知识图谱,让 AI 查询代码结构关系,而不是每次都依赖 grep、全文搜索和逐文件读取。
官方 README 中提到,它使用 Tree-sitter 对多语言代码进行 AST 解析,并在部分语言上结合 Hybrid LSP 做语义类型解析;知识图谱中包含函数、类、调用链、HTTP 路由、跨服务链接等结构化信息。数据在本地处理和持久化,官方说明是代码不会离开本机。

1.3.1. 工作原理
可以把它理解成“给代码库建立地图”:
代码仓库
│
▼
Tree-sitter / Hybrid LSP 解析源码
│
▼
提取代码实体(File、Class、Function、Route 等)
│
▼
分析代码关系(CALLS、IMPORTS、IMPLEMENTS、HTTP links 等)
│
▼
构建本地持久化知识图谱
│
▼
AI 通过 MCP 查询知识图谱
它记录的是代码事实(Fact),而不是 AI 总结出的架构故事。典型事实包括:
- 文件、模块、类、接口、函数等代码实体
- 函数调用关系(CALLS)
- import / module 依赖
- 类型引用和符号解析
- 实现关系(IMPLEMENTS)
- HTTP Route、跨服务 HTTP 调用等框架信息(取决于语言和框架支持)
这类信息的价值在于可验证。AI 不需要先猜“这个函数可能在哪”,而是可以直接问图谱:“谁调用了它?”“它依赖哪些模块?”“这个路由最终进了哪个 handler?”
1.3.2. 优势
相比传统的 grep + Read 工作流,Codebase Memory MCP 的优势在于:
- 一次解析,长期复用:代码结构被索引后,可以在后续会话中反复查询。
- 结构化查询更准确:调用链、依赖关系、入口路径比纯文本搜索更接近代码真实结构。
- 降低 Token 消耗:官方 README 在结构化查询示例中给出过“约 120x fewer tokens”的说法;它适用于特定结构化查询场景,不能简单理解为所有任务都固定节省 99%。
- 查询速度快:官方宣称结构化查询可达到亚毫秒级,实际速度仍取决于代码库规模、索引状态和查询类型。
- 本地运行:使用本地持久化存储,无需外部数据库或 API Key,适合对代码安全敏感的团队。
- 适合多仓协作:当多个基础库支撑多个业务仓库时,它能帮助 AI 更快理解平台边界、复用路径和跨仓依赖。
一句话总结:它不是让 AI “更会猜”,而是让 AI “少猜一点”。
1.4. 二者如何协同
| 维度 | Codebase Memory MCP | LLM Wiki |
|---|---|---|
| 核心对象 | 代码 | 文档与人类解释 |
| 主要方法 | 静态分析 + 结构化图谱 | LLM 阅读、整理、综合与维护 |
| 主要产物 | 代码知识图谱 | Markdown 知识文档 |
| 擅长回答 | “谁调用了谁?”“入口在哪里?”“依赖关系是什么?” | “为什么这样设计?”“模块职责是什么?”“历史取舍是什么?” |
| 可靠性来源 | 可查询、可追溯的代码事实 | 可阅读、可评审、可持续修订的知识文档 |
二者不是竞争关系,而是互补关系。
Codebase Memory MCP 负责回答“是什么(What)”。
它告诉 AI:有哪些类、哪些函数、哪些路由、谁调用谁、依赖关系是什么。它让 AI 站在代码事实上说话。
LLM Wiki 负责回答“为什么(Why)”。
它沉淀模块职责、设计背景、业务语义、架构取舍和历史上下文。它让 AI 不只是看见代码,还能理解代码背后的意图。
1.5. 推荐组合:事实层 + 知识层
如果只用 Codebase Memory MCP,AI 能更快找到代码路径,但仍然可能不知道业务背景和设计取舍。
如果只用 LLM Wiki,AI 能读到架构解释,但仍然可能无法确认当前代码是否已经变化。
所以更稳妥的组合是:
业务文档 / 会议纪要 / 设计文档
│
▼
LLM Wiki
形成知识层:背景、职责、设计取舍
代码仓库 / 基础库 / 业务仓库
│
▼
Codebase Memory MCP
形成事实层:实体、调用链、依赖、路由
│
▼
AI 编程助手
基于“事实 + 知识”进行问答、改造、排障和代码生成
这套组合拳的核心不是“多装几个工具”,而是建立一条清晰的知识生产线:
- 文档进入 LLM Wiki,沉淀为可读、可维护的知识。
- 代码进入 Codebase Memory MCP,沉淀为可查、可验证的事实。
- AI 编程助手同时读取两层上下文,减少重复探索,降低幻觉风险,提高跨仓研发效率。
评论