1. 缓存
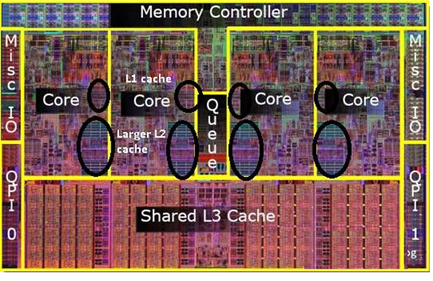
Cache Memory也被称为Cache,是存储器子系统的组成部分,存放着程序经常使用的指令和数据,这就是Cache的传统定义。从广义的角度上看,Cache是快设备为了缓解访问慢设备延时的预留的Buffer,从而可以在掩盖访问延时的同时,尽可能地提高数据传输率。 快和慢是一个相对概念,与微架构(Microarchitecture)中的 L1/L2/L3 Cache相比, DDR内存是一个慢速设备;在磁盘 I/O 系统中,DDR确是快速设备,在磁盘I/O系统中,仍在使用DDR内存作为磁介质的Cache。在一个微架构中,除了有L1/L2/L3 Cache之外,用于虚实地址转换的各级TLB, MOB( Memory Ordering Buffers)、在指令流水线中的ROB,Register File和BTB等等也是一种Cache。我们这里的Cache,是狭义 Cache,是CPU流水线和主存储器的 L1/L2/L3 Cache。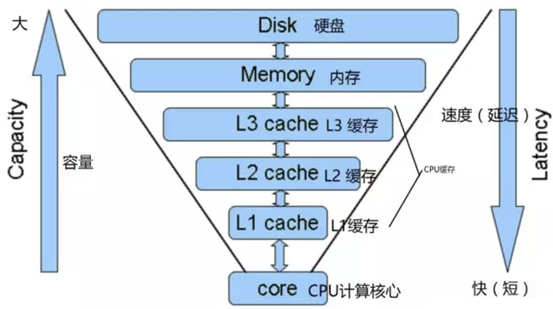
L1,L2,L3 指的都是CPU的缓存,比内存快,但是很昂贵,所以用作缓存,CPU查找数据的时候首先在L1,然后看L2,如果还没有,就到内存查找一些服务器还有L3 Cache,目的也是提高速度。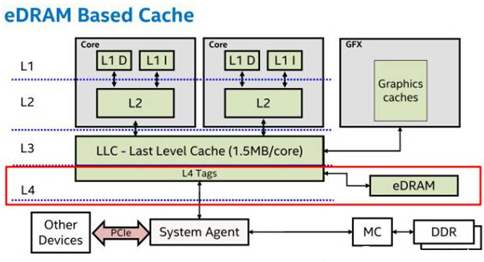
L1 cache、L2 cache、L3 cache 速度快,主要和其与 CPU 的距离、存储容量、制造工艺及数据预取机制有关:
- 物理位置靠近 CPU:L1-L3 cache 在位置上都离 CPU 核心越来越近,尤其是L1 cache通常集成在CPU内核内。这使得CPU在访问缓存时,数据传输路径短,信号传输延迟低,能快速获取数据和指令,就像在身边的物品更容易快速拿到。
- 较小的存储容量:缓存容量相对主存小很多,L1 cache通常几十KB-几百 KB,L2 cache几百KB-几MB,L3 cache几MB-几十 MB。较小的容量使得缓存的存储结构更紧凑,CPU查找数据时遍历的存储单元少,就像在小房间找东西比大仓库更容易、更快。
- 先进的制造工艺:缓存一般采用与CPU相同或更先进的制造工艺,使用高速的存储单元,这些存储单元的电子信号切换速度快,能快速响应CPU的读写请求,实现高速的数据存取。
1.1. L1 Cache
L1 Cache(一级缓存)是CPU第一层高速缓存,分为数据缓存和指令缓存。内置的L1高速缓存的容量和结构对CPU的性能影响较大,不过高速缓冲存储器均由静态RAM组成,结构较复杂,在CPU管芯面积不能太大的情况下,L1级高速缓存的容量不可能做得太大。一般服务器CPU的L1缓存的容量通常在32—256KB。
SRAM 速度快,不过在相同面积下其容量比其他类型内存小,且成本较高。而 L1 cache 集成在 CPU 内部,作为 CPU 和较低速内存(如 DRAM )之间的缓存,对速度要求极高。SRAM 的高速特性契合 L1 cache 需求,能让其快速响应 CPU 的数据和指令读取请求,减少 CPU 等待时间,提升运行效率。
1.1.1. 静态ram和动态ram
静态 RAM(SRAM)和动态 RAM(DRAM)的区别如下:
- 存储原理:
- 静态RAM:每个存储单元由四到六个晶体管组成双稳态触发器来记忆信息。只要供电正常,触发器就能稳定保持所存储的数据,无需刷新 。
- 动态RAM:每个存储单元由一个晶体管和一个电容构成。利用电容上存储的电荷来表示数据,由于电容存在漏电现象,电荷会逐渐流失,所以需周期性刷新补充电荷,以维持数据的正确性 。
- 读写速度:
- 静态RAM:存储单元结构简单且无需刷新,数据存取速度快,能快速响应 CPU 的数据请求,常被用作高速缓存(如 L1 - L3 cache) 。
- 动态RAM:因存在刷新操作及存储结构相对复杂等因素,读写速度比静态RAM慢 。
- 集成度与容量:
- 静态RAM:每个存储单元由多个晶体管组成,占用芯片面积大,集成度低,存储容量相对较小 。
- 动态RAM:每个存储单元仅由一个晶体管和一个电容组成,占用芯片面积小,集成度高,可实现大容量存储,常见的计算机内存条多采用动态RAM 。
- 功耗:
- 静态RAM:存储单元始终处于稳定状态,只要供电就有电流消耗,功耗相对较高 。
- 动态RAM:仅在读写和刷新操作时消耗较多功率,平时电容保持电荷状态时功耗低,整体功耗比静态RAM低 。
- 成本:
- 静态RAM:因集成度低、制造工艺复杂、单位存储容量成本高,价格较贵 。
- 动态RAM:由于集成度高、单位存储容量成本低,在大容量存储需求下性价比高,价格相对便宜
1.2. L2 Cache
L2 Cache(二级缓存)是CPU的第二层高速缓存,分内部和外部两种芯片。内部的芯片二级缓存运行速度与主频相同,而外部的二级缓存则只有主频的一半。L2高速缓存容量也会影响CPU的性能,原则是越大越好,现在家庭用CPU容量最大的是512KB,而服务器和工作站上用CPU的L2高速缓存更高达256-1MB,有的高达2MB或者3MB。
1.3. L3 Cache
L3 Cache(三级缓存),分为两种,早期的是外置,现在的都是内置的。而实际作用即是,L3缓存的应用可以进一步降低内存延迟,同时提升大数据量计算时处理器的性能。降低内存延迟和提升大数据量计算能力,对游戏都很有帮助。而在服务器领域增加L3缓存,在性能方面仍然有显著的提升。具有较大L3缓存的配置利用物理内存会更有效,比较慢的磁盘I/O子系统,可以处理更多的数据请求。具有较大L3缓存的处理器,提供更有效的文件系统缓存行为及较短消息和处理器队列长度。
1.4. 局部性原理
缓存基于局部性原理,局部性有两种,即时间局部性和空间局部性。
时间局部性:当一个数据被访问后,它很有可能在不久的将来被再次访问,比如循环代码中的数据或指令。
空间局部性:当程序访问地址为x的数据时,很有可能会紧接着访问x周围的数据,比如遍历数组或指令的顺序执行。
由于这两种局部性存在大多数的程序中,硬件系统可以很好地预测哪些数据可以放入缓存,从而可以运行得很好。
1.5. 缓存一致性
多CPU系统中,每个CPU核心通常有自己的私有缓存(如L1、L2缓存),而共享主内存。缓存的存在是为了加速数据访问,减少访问主存的延迟。但这也带来了问题:当一个CPU修改了自己缓存中的数据时,其他CPU的缓存中同一数据的副本就会变得不一致。如何确保所有CPU看到的内存视图一致,这就是缓存一致性需要解决的问题。
缓存一致性要求满足以下几点:
- 写传播(Write Propagation):任何CPU对某个内存位置的写操作必须最终被其他CPU看到。
- 事务串行化(Transaction Serialization):所有CPU对同一内存位置的读写操作顺序在所有CPU看来是一致的。
最著名的缓存一致性协议应该是MESI协议,MESI代表缓存行的四种状态:
- Modified(已修改):缓存行已被修改,与主存不同,且只有当前缓存拥有该数据。
- Exclusive(独占):缓存行与主存一致,且未被其他缓存持有。
- Shared(共享):缓存行与主存一致,可能被多个缓存共享。
- Invalid(无效):缓存行数据无效,需要重新从主存或其他缓存获取。
1.5.1. 状态转换
CPU A写数据:
1. 若原状态为S或I→发送“无效化”信号给其他缓存,只有收到所有确认后,将状态改为M。
2. 若原状态为E→直接改为M。
3. 假设CPU A和CPU B同时发起对同一缓存行的写请求,则总线控制器(或目录协议)会序列化请求,只允许一个CPU先获得独占权。这种序列化是硬件层面的。
CPU B读数据:
1. 若其他缓存有M状态→触发回写主存,并转为S状态。
2. 若其他缓存有S/E状态→共享数据,状态转为S。
1.5.2. 协议变种
- MOESI:ARM架构使用,增加Owned(O)状态,允许缓存持有修改数据并与其他缓存共享,延迟写回主存。
- MESIF(Intel使用):x86架构,增加Forward(F)状态,指定一个缓存作为数据提供者,减少总线流量。
1.5.3. 缓存一致性实现方式
1.5.3.1. 监听式协议(Snooping Protocol)
- 适用场景:基于总线的小规模多核系统(如单插槽CPU)。
- 原理:所有缓存监听总线上的事务(如读/写请求),根据规则更新自身状态。
- 示例:
- CPU A写数据→广播“无效化”消息→其他缓存标记该数据为I。
1.5.3.2. 目录式协议(Directory Protocol)
- 适用场景:NUMA架构的大规模多处理器系统(如多路服务器)。
- 原理:中央目录记录缓存行状态(如哪些节点缓存了数据),减少广播开销。
- 步骤:
- CPU请求数据→查询目录获取持有者列表。
- 目录协调数据传递和状态更新(如发送无效化信号给特定节点)。
1.5.3.3. 性能分析
1.5.3.3.1. 写独占缓存时间
处于E状态的缓存写入时间应该非常快,等同于本地缓存的写入延迟,不需要总线交互,因此时间大约是1到几个CPU周期,具体取决于处理器的设计。
- L1缓存:1-3个CPU周期(约0.3-1 ns,假设3 GHz主频)。
- L2缓存:5-10个周期(约1.7-3.3 ns)。
- L3缓存:20-40个周期(约6.7-13.3 ns)。
3GHZ主频,一个CPU周期大约为1/(3*10^9)=0.3ns
1.5.3.3.2. 写共享缓存的时间组成
- 总线仲裁延迟:多个核心竞争总线时的排队时间(通常10-50纳秒,取决于总线负载)。
- 信号传播延迟:广播
Invalidate信号到所有缓存控制器的时间(现代CPU片上互联延迟约5-20纳秒)。 - 确认响应延迟:等待其他CPU确认无效化完成的时间(约20-100纳秒,取决于核心数量和拓扑)。
总延迟范围:
- 低竞争场景:约30-100纳秒。
- 高竞争场景(如多核争抢同一缓存行):可能超过200纳秒
1.5.3.3.3. 直接写主存时间组成
- DRAM访问延迟:现代DDR4/DDR5内存的典型延迟为70-100纳秒。
- 总线传输时间:数据从内存控制器到CPU的传输(约 20-50纳秒)。
- 协议开销:若涉及缓存一致性,仍需总线交互(如回写脏数据)。
总延迟范围:
- 显式写主存(非缓存):约 100-150纳秒。
- 缓存未命中后写回:可能叠加缓存加载时间,总延迟 200纳秒以上。
1.5.3.4. 对比
| 指标 | 监听式协议(Snooping) | 目录式协议(Directory) |
|---|---|---|
| 扩展性 | 差(总线带宽限制,适合≤32核) | 优(目录记录状态,适合大规模多核) |
| 总线流量 | 高(广播所有消息) | 低(仅通知相关节点) |
| 典型应用 | 桌面CPU(如Intel Core系列) | 服务器CPU(如AMD EPYC) |
| 延迟 | 低(直接总线访问) | 较高(需查询目录) |
1.5.4. 内存屏障(Memory Barrier)
- 作用:强制内存操作顺序,防止CPU/编译器重排序破坏一致性,同时确保缓存中的数据及时刷新到主内存,以及从主内存中读取最新的数据。
- 类型:
- 写屏障:确保屏障前的写操作先于屏障后的写操作提交。
- 读屏障:确保屏障后的读操作能看到屏障前所有写操作的结果。
// 线程1
data = 42;
memory_barrier(); // 确保data写入在flag之前
flag = 1;
// 线程2
while (flag == 0); // 自旋等待
memory_barrier(); // 确保读取flag后能读取到最新的data
printf("%d", data);
1.5.4.1. 指令重排
现代的编译器和CPU为了提高程序的执行性能,会对指令进行重排序。指令重排序是指编译器或CPU在不改变程序单线程执行结果的前提下,对指令的执行顺序进行调整。
在没有内存屏障的情况下,编译器或CPU可能会对线程1中的指令进行重排序,将
flag = 1;提前到data = 42;之前执行。当发生这种重排序时,线程2可能会在data还未被正确赋值为42时,就通过检查flag的值(此时flag已经被置为1)进入后续代码读取data,从而读到错误的值。线程 1 中的内存屏障保证了
data的写入操作一定在flag的写入操作之前完成,并且数据会被刷新到主内存。线程 2 中的内存屏障保证了在读取flag之后,能从主内存中读取到最新的data值。
1.5.5. 软件协同机制
1.5.5.1. 原子操作
- CAS(Compare-And-Swap):硬件支持的原子指令,确保“读-改-写”操作不可分割。
// 原子地比较并更新值
int atomic_cas(int* ptr, int expect, int new_val) {
// 若*ptr == expect,则*ptr = new_val,返回旧值
}
1.5.5.2. 锁机制
- 自旋锁(Spinlock):忙等待锁,适用于短临界区。
- 互斥锁(Mutex):阻塞等待锁,减少CPU空转。
1.5.5.3. 无锁编程
基于原子操作和内存屏障实现数据结构(如无锁队列),避免锁竞争。
评论