1. 让 AI coding agent 真正读懂你的代码仓
最近在研究如何让 Claude Code 在跨多个repo工作时不那么"失忆",整理了一下Deepwiki和llms.txt方案的来龙去脉、实现方式和适用边界。
1.1. 趣闻
AI火了,tailwindcss火了,下载量竹节攀升,但是tailwind公司收入骤减 80%。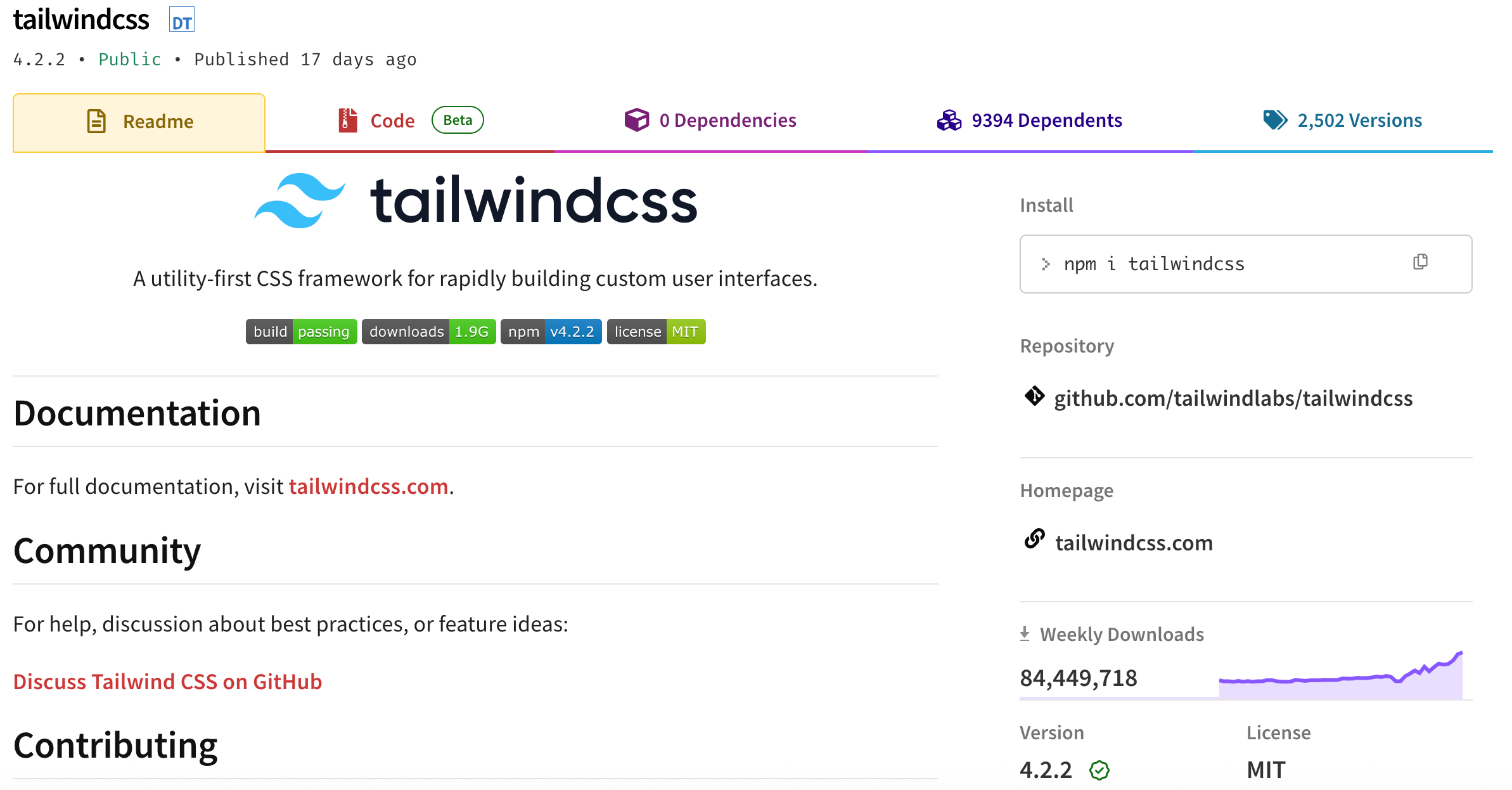
2025年11月,一个开发者在Tailwind项目里贡献了一个PR,想要给 Tailwind 网站增加一个llms.txt ,方便 AI 大模型读取项目文档,最终被作者拒绝合入了。
大家用AI写代码,用AI debug,很少有人还会去看原始文档了。
1.2. DeepWiki:GitHub 仓库的 AI 自动 Wiki
DeepWiki 是 Cognition(Devin 的开发商)推出的工具,能为任意公开 GitHub 仓库自动生成交互式 Wiki 文档。它会抓取仓库的代码、注释、README 等内容,用 AI 生成结构化的架构说明、模块介绍和调用关系图,让开发者和 AI agent 快速理解一个陌生仓库。
1.2.1. 怎么用
浏览器直接访问
把 GitHub URL 的 github.com 替换为 deepwiki.com 即可:
https://github.com/anthropics/anthropic-sdk-python
↓
https://deepwiki.com/anthropics/anthropic-sdk-python
进入后可以看到自动生成的侧边栏目录、各模块的说明文档、以及模块间的依赖关系图。右上角有一个对话框,支持对该仓库直接提问。
MCP 集成(供 AI agent 使用)
DeepWiki 提供官方 MCP server,可以让 Claude Code、Cursor 等工具直接查询任意 GitHub 仓库的 Wiki:
{
"mcpServers": {
"deepwiki": {
"type": "http",
"url": "https://mcp.deepwiki.com/mcp"
}
}
}
接入后,agent 可以使用三个核心工具:
read_wiki_structure:获取仓库的页面目录树,用于导航和了解有哪些章节read_wiki_contents:读取某个 Wiki 页面的完整内容(AI 生成的文档,非原始代码)ask_question:用自然语言对指定仓库提问,内部检索 Wiki 后由 LLM 生成回答
read_wiki_structure和read_wiki_contents适合让 agent 系统性地了解一个仓库的整体结构;ask_question适合针对性地查询某个具体问题。
1.3. AI agent 为什么需要 llms.txt
LLM 的 context window 有限,直接把整个 repo 塞进去不现实。更麻烦的是:HTML 页面、Javadoc、各种框架生成的文档,对 LLM 来说信噪比极低——导航栏、广告、JS 动态内容全是噪声。
llms.txt 的核心思想很简单:提供一个结构化的入口文件,让 agent 知道"这个项目/服务的关键信息在哪里",然后按需 fetch,而不是盲目爬取。
类比:robots.txt 告诉爬虫"能爬哪里",llms.txt 告诉 LLM "该看哪里"。但后者是主动引导,不是访问控制。
1.3.1. 规范解析:它到底是什么格式
由 Answer.AI 的 Jeremy Howard 在 2024 年 9 月提出,托管在 llmstxt.org。格式是 Markdown,放在项目根目录的 /llms.txt。
最小结构:
# ProjectName
> 一句话说明项目是什么、解决什么问题
## Docs
- [快速开始](./docs/quickstart.md): 5 分钟上手
- [API 参考](./docs/api.md): 完整接口定义
## Examples
- [示例 1](./examples/demo.md): 典型用法
## Optional
- [Changelog](./CHANGELOG.md): 版本记录
有两个变体:
llms.txt(精简版,只含核心链接)llms-full.txt(完整版,把所有 optional 链接展开内联)。
- 对于 agent 来说,
llms.txt+ 按需 fetch 单个文件,是更省 token 的用法。 - 所有链接指向的文件最好是 Markdown,而不是 HTML。Markdown 对 LLM 来说 token 效率更高,且无噪声。
1.4. DeepWiki vs llms.txt:怎么选
1.4.1. 宏观对比
| 维度 | DeepWiki | llms.txt |
|---|---|---|
| 配置成本 | 零配置,自动抓取 | 需手动维护 |
| 主要受众 | 人 + AI(可视化更好) | AI agent(token 效率更高) |
| 多 repo 协作 | 有关联但不结构化 | 每个服务自己维护,agent 按需聚合 |
| CI 集成 | 不支持 | 可以自动生成 |
| 适合场景 | 理解陌生开源项目 | 跨服务 AI 辅助开发 |
1.4.2. 信息精度:DeepWiki 的根本局限
DeepWiki 生成的 wiki 是对代码的 AI 理解,存在信息损耗和失真。ask_question 经过两次 AI 处理(索引时一次 + 回答时一次),每次都有损耗的风险。对于 coding agent 来说,生成代码最依赖的是精确信息,而不是高质量的自然语言描述。
| 信息类型 | DeepWiki wiki | llms.txt 指向原始文件 |
|---|---|---|
| proto/接口定义 | AI 描述,可能不精确 | 原始 .proto 文件,精确 |
| 字段约束、枚举值 | 容易被概括掉 | 完整保留 |
| 跨服务消息格式 | 可能合并描述 | 原始 schema |
| 版本变更 | 依赖 AI 总结 | CHANGELOG 原文 |
| 重要约束(如"禁止用 float") | 可能被忽略 | 你写进去就一定在 |
llms.txt 的核心优势是你对内容有完全控制。例如下面这段约束,DeepWiki 自动生成时大概率会被概括成"该服务支持幂等操作",丢失对 agent 最关键的细节:
## 重要约束
- 金额字段禁止 float/double,必须 BigDecimal
- idempotencyKey 由调用方生成,格式:{bizType}_{orderId}_{timestamp}
- 退款接口幂等窗口 24h,超时需重新申请
1.4.3. 分层使用
两者不互斥,适合分层配合:
- DeepWiki 层:负责结构索引和自然语言问答,适合 agent 做初步探索和架构理解
- llms.txt 层:负责精确的接口契约、约束和跨服务依赖,作为 agent 生成代码的
ground truth
单独用 DeepWiki MCP 做跨 repo 开发辅助,风险在于 agent 可能拿到"大体正确但细节错误"的信息——这在接口调用场景里比完全不知道更危险。
1.5. 实践:如何为代码仓写一个好的 llms.txt
以一个内部微服务为例,重点放在 agent 跨服务开发时最需要的信息:
# PaymentService
> 负责订单支付、退款、对账的核心服务。基于 Spring Boot,通过 gRPC 对外暴露接口。
## 重要约束
- 所有金额字段使用 BigDecimal,禁止 float/double
- 接口幂等性由调用方传入 idempotencyKey 保证
- 不直接依赖 OrderService,通过 MQ 消费订单事件
## API 文档
- [gRPC 接口定义](./proto/payment.proto): 完整 proto 文件
- [REST 回调接口](./docs/callback-api.md): 支付网关回调格式
## 核心模块
- [支付流程](./docs/payment-flow.md): 状态机设计
- [退款逻辑](./docs/refund.md): 部分退款和全额退款的处理差异
## 跨服务依赖
- [与 OrderService 的集成](./docs/integration-order.md): 消息格式和主题名
- [与 NotifyService 的集成](./docs/integration-notify.md): 通知触发时机
## Optional
- [本地开发指南](./docs/local-dev.md): 数据库初始化和环境变量
- [Changelog](./CHANGELOG.md): 接口变更记录
写 llms.txt 的原则:它是"目录"不是"文档"。每条链接对应一个可独立阅读的 Markdown 文件,llms.txt 本身保持精简。把所有内容堆在这一个文件里会浪费 context window。
1.6. 与 MCP 集成:让 agent 按需拉取
目前最实用的集成方案是通过 mcpdoc MCP server,把多个服务的 llms.txt 聚合起来喂给 Claude Code 或 Cursor。
{
"mcpServers": {
"internal-docs": {
"command": "uvx",
"args": [
"--from", "mcpdoc", "mcpdoc",
"--urls",
"PaymentService:http://internal/payment/llms.txt",
"OrderService:http://internal/order/llms.txt",
"NotifyService:http://internal/notify/llms.txt",
"--transport", "stdio"
]
}
}
}
这样 agent 在处理跨服务任务时,可以主动 fetch 对应服务的文档,而不是依赖训练时的知识(那往往是过时的或根本没有的)。
Claude Code 的注册方式:
claude mcp add internal-docs --transport stdio -- \
uvx --from mcpdoc mcpdoc \
--urls "Payment:http://internal/payment/llms.txt" \
--transport stdio
工作流规则
在AGENTS.md或Rules中添加,对于任何关于支付的问题:
- 调用 list_doc_sources 查看可用的文档源
- 调用 fetch_docs 读取相关的 llms.txt
- 选择并获取最相关的 .md 页面
- 基于获取的文档回答,并引用来源 URL
📊 开发者经验总结
- 文档优先策略 - 让 AI 在回答前先查询文档,减少幻觉
- 细粒度控制 - 使用 --allowed-domains 限制可访问域名,提升安全性
- 多框架支持 - 同一 MCP 服务器配置可用于 Cursor、Windsurf、Claude 等多个工具
- 版本管理 - llms.txt 随文档自动更新,无需手动维护
1.7. 踩坑记录
1.7.1. 坑 1:链接文件不是 Markdown
早期把部分链接指向 Confluence 页面(HTML),agent fetch 回来全是导航栏噪声。改成把关键文档 export 为 Markdown 放进 repo,效果立刻好很多。
1.7.2. 坑 2:llms.txt 内容太多
第一版把服务的详细说明都写在 llms.txt 里,结果 agent 每次都把它全部读进 context,挤占了提问的空间。现在保持 llms.txt 在 50 行以内,细节全部拆到独立 Markdown 文件。
1.7.3. 坑 3:文件不同步
接口改了但 llms.txt 忘了更新,agent 照着旧文档生成代码。解决方案:在 CI 里加一个简单检查,如果 proto/ 或 docs/ 有变更,提醒 review llms.txt。完全自动生成也是一个方向,但需要维护生成脚本。
参考:llmstxt.org · AnswerDotAI/llms-txt · Google ADK Docs · llms-txt-hub
评论