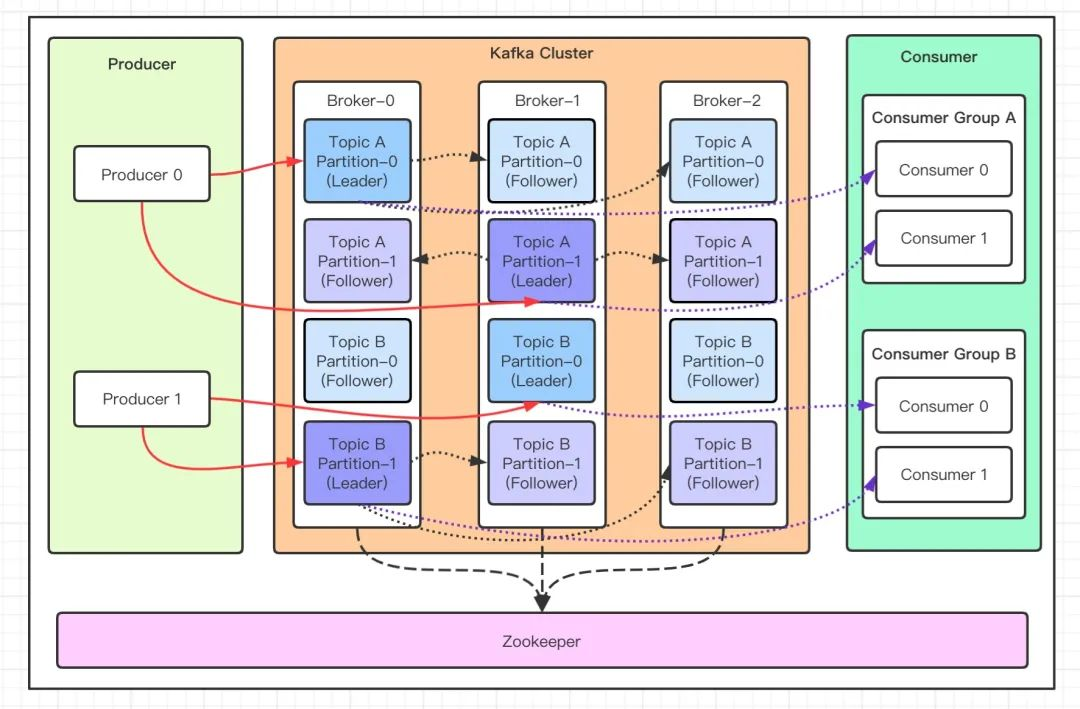
1. topic
kafka将消息以topic为单位进行分类,一个topic就是一个逻辑队列。类比于数据库中的分库。
2. partition
为了实现扩展性,提高并发能力,kafka将一个逻辑队列(topic)划分为多个partition,每个partition保存一个topic中的部分数据,每一个partition中的顺序是有序的。类比于数据库中的分表。
3. Replica
副本,为实现备份的功能,保证集群中的某个节点发生故障时,该节点上的 Partition 数据不丢失,且 Kafka 仍然能够继续工作,Kafka 提供了副本机制,一个 Topic 的每个partition都有若干个副本,一个 Leader和若干个 Follower。
4. Leader
每个分区多个副本的“主”副本,生产者发送数据的对象,以及消费者消费数据的对象,都是 Leader。
思考:
kafka不支持数据库类似的读写分离能力。kafka的每个broker节点其实即某个partion的leader,又是其他partition的follower。Kafka 的设计初衷是为了实现高吞吐量的消息传递,而不是传统数据库那样强调读写分离以满足复杂的查询和写入场景。它通过顺序读写磁盘、分区机制等设计来实现高效的数据写入和读取。
5. Follower
每个分区多个副本的“从”副本,实时从 Leader 中同步数据,保持和 Leader 数据的同步。Leader 发生故障时,某个 Follower 还会成为新的 Leader。
6. Offset
消费者消费的位置信息,监控数据消费到什么位置,当消费者挂掉再重新恢复的时候,可以从消费位置继续消费。
7. Zookeeper
Kafka 集群能够正常工作,需要依赖于Zookeeper,Zookeeper 帮助 Kafka 存储和管理集群信息。
8. broker
kafka集群中包含一个或者多个服务实例(节点),这种服务实例被称为broker,用来存储消息数据。
9. producer
消息的生产者,负责发布消息到kafka的broker中。
10. consumer
消息的消费者,负责从kafka的broker中获取消息并处理。
11. consumer group
消费者组,每一个consumer都属于一个特定的consumer group,某个topic下的某个partition只会同时被consumer group中的一个consumer消费。
评论