这里我们以网络服务用的最多的kafka组件为例,来介绍下其实现原理,已经如何在知晓原理的情况下用好kafka。
1. producer
enable.idompotence: 控制producer端开启幂等和事务能力。开启幂等后能够保证消息不重复。transactional.id为生产者提供了一个唯一的事务标识符。通过这个标识符,Kafka 能够跟踪和管理生产者的事务状态。当生产者使用事务性发送时,Kafka 会将具有相同transactional.id的所有消息视为一个事务单元。这确保了在事务范围内的消息要么全部成功提交,要么全部回滚,从而保证了事务的原子性。acks:此配置是 Producer 在确认一个请求发送完成之前需要收到的反馈信息的数量。 这个参数是为了保证发送请求的可靠性max.request.size参数来控制消息的最大大小。这个参数指定了生产者在单个请求中发送的消息的总大小上限(包括消息体、键、头部等)。默认值为1048576B,即1MBretries:配置生产者重试次数,对于可重试异常,那么只要在规定的次数内自行恢复了,就不会抛出异常,默认是0,不重试。retry.backoff.ms用来设定两次重试之间的时间间隔,默认值100。request.timeout.ms:配置Producer等待请求响应的最长时间,默认值为30000(ms),请求超时之后可以进行重试。注意这个参数需要比broker端参数replica.lag.time.max.ms的值要大,这样可以减少因客户端重试而引起的消息重复的概率。
2. consumer
max-poll-record: 消费者每次从Kafka拉取的消息数量max.poll.records:消费者一次最多拉取的数据条数max.poll.interval.ms: 消费者每次从Kafka拉取数据的时间间隔,超时会认为消费者故障,触发rebalance,默认值为300000session.timeout.ms:会话超时间,如果消费者在这个时间内没有发送心跳消息,kafka会认为这个消费者故障,触发rebalance,默认值为10000heartbeat-interval:发送心跳的间时间,一般设置为session.timeout.ms的三分之一,默认为3000request.timeout.ms: 客户端等待响应的最长时间,默认为30000fetch.min.bytes:消费者从 broker 拉取消息时,每次请求最少返回的字节数。如果 broker 中可用的数据量小于这个值,broker 会等待直到有足够的数据再返回响应。fetch.max.bytes:单次拉取数据的最大大小,应该要大于producer的max.request.sizeisolation.level:控制消费者读取事务性消息的隔离级别。默认值是read_uncommittedread_uncommitted(可以读取未提交的事务消息)。read_committed(只能读取已提交的事务消息)。
2.1. 消费任务超时
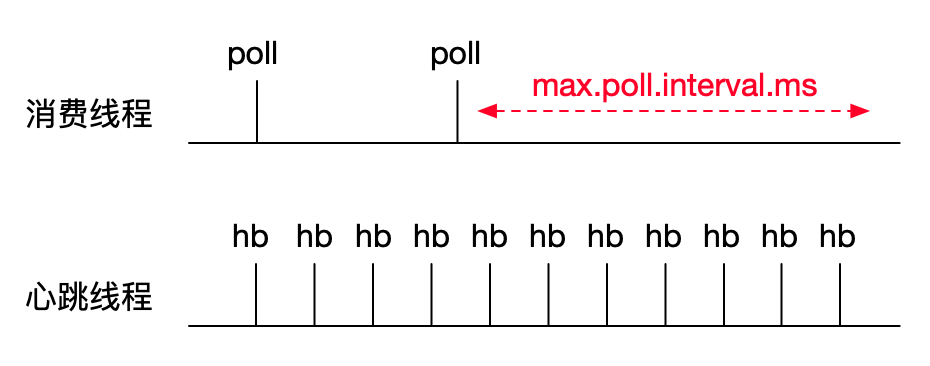
实际配置参数的时候建议要考虑应用的处理能力,当应用处理能力不足时,可以适当减少max-poll-record或提高max.poll.interval.ms时长。
2.2. 心跳任务超时
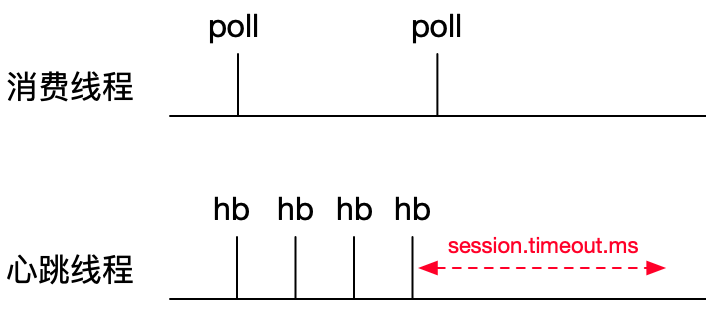
考虑到某些业务的复杂度,消费任务时间处理比较久,max.poll.interval.ms配置值可能比较大,在client故障的场景下,可能需要等待较长的时间才能完成故障切换。为了保证能提供client故障判定的速度,kafka引入独立的心跳机制实现快速故障切换。
2.3. 总结
kafka的poll超时机制和心跳超时机制共同作用,保证了在允许消费者可以花较长的时间处理消息的同时,可以在较短的时间实现故障检测和故障切换。
2.4. 提交offset
enable.auto.commit:是否自动提交消费偏移量。设置为true时,消费者会定期自动提交偏移量;设置为false时,需要手动提交偏移量。auto.commit.interval.ms:当自动提交偏移量时,指定提交的时间间隔(毫秒)。auto-offset-reset:earliest:当各分区下有已提交的 offset 时,从提交的 offset 开始消费;无提交的 offset 时,从头开始消费。latest:当各分区下有已提交的 offset 时,从提交的 offset 开始消费;无提交的 offset 时,消费新产生的该分区下的数据。none:topic 各分区都存在已提交的 offset 时,从 offset 后开始消费;只要有一个分区不存在已提交的 offset,则抛出异常。
当设置自动提交时,consumer会在每次拉取新数据前判断时间间隔是否到了来决定是否自动提交偏移量。自动提交会存在数据丢失和重复消费的风险
评论