1. 生产可靠
为保证Producer发送的数据,能可靠地发送到指定的Topic,Topic的每个Partition收到Producer发送的数据后,都需要向Producer发送ACK(ACKnowledge 确认收到)。如果Producer收到ACK,就会进行下一轮的发送,否则重新发送数据。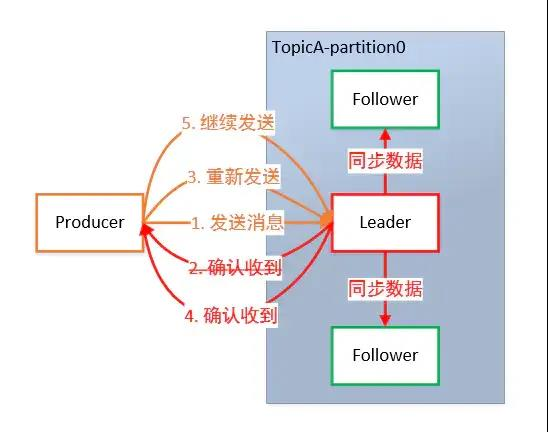
1.1. 副本同步策略
何时发送ACK?确保有Follower与Leader同步完成,Leader再发送ACK,这样才能保证Leader挂掉之后,能在Follower中选举出新的Leader而不丢数据。多少个Follower同步完成后发送 ACK?全部Follower同步完成,再发送ACK。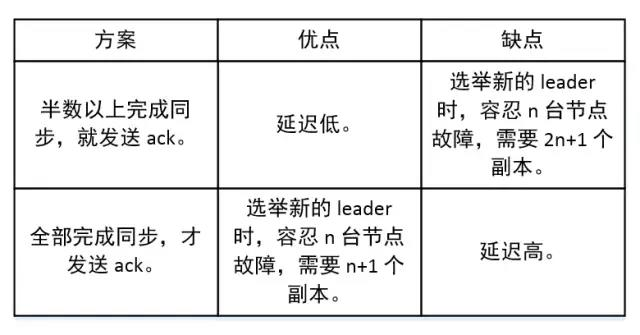
采用第二种方案,所有Follower完成同步,Producer才能继续发送数据,设想有一个Follower因为某种原因出现故障,那Leader就要一直等到它完成同步。这个问题怎么解决?Leader维护了一个动态的in-sync replica set(ISR):和Leader保持同步的Follower集合。当ISR集合中的Follower完成数据的同步之后,Leader 就会给 Follower 发送 ACK。如果 Follower 长时间未向 Leader 同步数据,则该 Follower 将被踢出 ISR 集合,该时间阈值由replica.lag.time.max.ms参数设定。Leader发生故障后,就会从ISR中选举出新的 Leader。
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等ISR中的Follower全部接受成功。所以 Kafka 为用户提供了三种可靠性级别,用户根据可靠性和延迟的要求进行权衡,选择以下的配置。
- 0:Producer不等待Broker的ACK,这提供了最低延迟,Broker一收到数据还没有写入磁盘就已经返回,当Broker故障时有可能丢失数据。
- 1:Producer等待Broker的ACK,Partition的Leader落盘成功后返回 ACK,如果在Follower同步成功之前 Leader 故障,那么将会丢失数据。
- -1(all):Producer 等待 Broker 的 ACK,Partition 的 Leader 和 Follower 全部落盘成功后才返回 ACK。但是在 Broker 发送 ACK 时,Leader 发生故障,则会造成数据重复。
-1的时候能够保证at least once,但不能保证exactly once
1.2. 故障处理细节
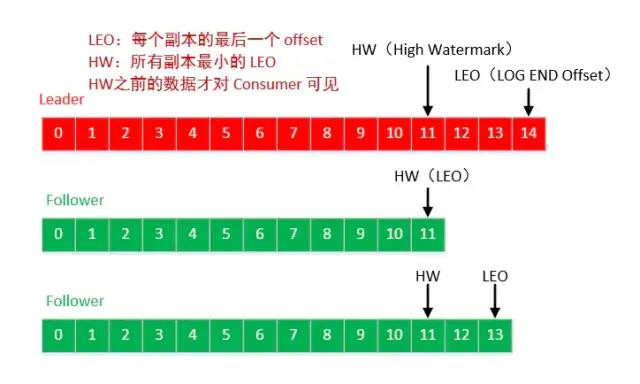
- LEO:每个副本最大的Offset。
- HW:消费者能见到的最大的Offset,ISR队列中最小的 LEO。
Follower 故障:Follower发生故障后会被临时踢出ISR集合,待该Follower恢复后,Follower会读取本地磁盘记录的上次的 HW,并将 log 文件高于 HW 的部分截取掉,从HW开始向 Leader 进行同步数据操作。等该 Follower的LEO大于等于该Partition的HW,即Follower追上Leader后,就可以重新加入ISR了。
Leader 故障:Leader发生故障后,会从ISR中选出一个新的 Leader,之后,为保证多个副本之间的数据一致性,其余的 Follower 会先将各自的 log 文件高于 HW 的部分截掉,然后从新的 Leader 同步数据。
HW和数据的同步是独立的,HW只能保证数据的一致性,无法保证不丢数据。
2. 消费可靠
由于Consumer在消费过程中可能会出现断电宕机等故障,Consumer恢复后,需要从故障前的位置继续消费。所以Consumer需要实时记录自己消费到了哪个Offset,以便故障恢复后继续消费。
Kafka 0.9 版本之前,Consumer默认将Offset保存在 Zookeeper 中,从 0.9 版本开始,Consumer 默认将Offset 保存在Kafka 一个内置的Topic中,该Topic为 __consumer_offsets。
Kafka 使用特定的哈希算法来确定消费者组的偏移量存储在__consumer_offsets主题的哪个分区中。通常,这个算法会考虑消费者组 ID、主题名称和分区编号等因素进行哈希计算,然后根据计算结果确定存储分区。__consumer_offsets主题的每个分区中存储了多个键值对,其中键通常由消费者组 ID、主题名称和分区编号组成,值则是具体的偏移量数值以及其他相关的元数据信息。
3. controller和zookeeper
https://www.51cto.com/article/754629.html
3.1. Zookeeper
3.1.1. 存储元数据
- Zookeeper 主要负责存储和管理 Kafka 集群的元数据信息,如broker列表、主题列表、分区分配等。在副本的leader选举过程中,controller需要从Zookeeper中获取这些元数据信息,以便确定哪些分区需要进行领导者选举。
3.1.2. Controller和coodinator的选举(如果当前 controller 宕机)
- 在 Kafka 集群中,当前 controller 宕机时,其他brokers会竞争成为新的controller。
- 这个过程依赖于Zookeeper。Brokers会在Zookeeper中注册一个临时节点,用于竞选 controller。Brokers 通过在Zookeeper中创建临时节点来竞争controller角色,Zookeeper会保证只有一个节点能够成功创建,第一个成功创建临时节点的broker成为新的controller。
详细过程如下:
- 注册Controller节点当Kafka集群启动时,每个Broker都会尝试在Zookeeper中的/controller路径下创建一个临时节点。因为同一时刻只能存在一个/controller 节点,所以只有一个 Broker 成功创建节点并成为Controller。其他 Broker 会收到节点创建失败的通知,然后转为观察者(Observer)状态,监视Controller节点路径的变化。
- 监听 Controller 节点所有非Controller的 Broker 都会在 Zookeeper 中对 /controller 路径设置一个 Watcher 事件。这样当Controller节点发生变化时(例如,Controller失效),所有非Controller就会收到一个 Watcher 事件。
- 选举新的Controller当某个Broker接收到Controller节点变化的通知后,它会再次尝试在 Zookeeper 中的/controller 路径下创建一个临时节点。与启动时的过程类似,只有一个 Broker 能够成功创建节点并成为新的Controller。新Controller会在选举成功后接管集群元数据的管理工作。
- 更新集群元数据新Controller在选举成功后需要更新集群元数据,包括分区状态、副本状态等。同时,新控制器会通知所有相关的 Broker 更新它们的元数据信息。这样,集群中的所有 Broker 都能够知道新Controller的身份,并进行协同工作。
注意:临时节点的特点是在创建它的客户端(即 Broker节点)断开连接时,它会自动被 Zookeeper 删除。这种机制保证了只有一个Broker节点能够成为控制器,以避免多个控制器同时对集群元数据进行操作引发的问题。
3.2. Controller
3.2.1. 存储数据
- 分区的leader和ISR信息
- 跟踪正在进行的leader选举和重分配的分区列表
- 副本状态变化等动态信息
3.2.2. 作用
Controller是Kafka集群中的一个特殊broker,它负责管理整个集群的状态。它承担着主题创建、分区分配、副本选举等关键任务,直接参与到 Kafka 的核心业务流程中。Controller能够快速响应集群中的各种变化,并及时做出相应的调整,以保证集群的高可用性和稳定性。
- Broker状态管理:Controller会跟踪集群中所有Broker的在线状态,并在Broker宕机或者恢复时更新集群的状态。
- 分区状态管理:当新的Topic被创建,或者已有的Topic被删除时,Controller会负责管理这些变化,并更新集群的状态。
- 分区领导者选举:当一台Broker节点宕机时,并且宕机的机器上包含分区领导者副本时,Controller会负责对其上的所有Partition进行新的领导者选举。
- 副本状态管理:Controller负责管理Partition的ISR列表,当Follower副本无法及时跟随Leader副本时,Controller会将其从ISR列表中移除。
- 分区重平衡:当添加或删除Broker节点时,Controller会负责对Partition的分布进行重平衡,以确保数据的均匀分布。
- 存储集群元数据:Controller保存了集群中最全的元数据信息,并通过发送请求同步到其他Broker上面。
4. broker
- 数据存储:每个非Controller节点都存储一部分数据,这部分数据是由Topic的Partition组成的。这意味着,每个Broker都保存了特定Partition的所有数据,不论这个Partition是Leader还是Follower。
- 数据复制:为了保证数据的可靠性,Kafka系统通过数据复制机制在多个Broker之间备份数据。每个Topic的Partition都有一个Leader和多个Follower。Leader负责处理所有的客户端读写请求,而Follower负责从Leader复制数据。在这个过程中,非Controller节点既可以是Leader也可以是Follower。
- 处理客户端请求:非Controller节点(leader节点)负责处理来自Producer和Consumer的请求。对于Producer的写请求,Broker会将数据写入对应的Partition。对于Consumer的读请求,Broker会从对应的Partition读取数据。
- 参与Leader选举:当Partition的Leader节点出现故障时,非Controller节点可能被选举为新的Leader节点。虽然Leader选举过程由Controller节点协调,但所有的非Controller节点都需要参与这个过程。
- 故障恢复:当某个Broker宕机时,Kafka会自动重新分配其上的Partition的Leader角色给其他的Broker,这也是非Controller节点的重要职责之一。
5. coordinator
5.1. 分类
5.1.1. consumer group coordinator
负责协调和管理消费者组,本质上是由broker充当的,每个consumer group都会有一个对应的broker充当其coordinator,主要负责以下功能:
- coordinator负责接收这个consumer group里面的所有consumer的心跳,如果发现某个consumer失联了,coordinator就会触发rebalance。
- 维护消费者组的成员信息,包括消费者ID,消费进度,还会处理消费者的joinGroup和leave Group请求并触发rebalance。
- 根据消费者组中消费者的数量以及topic对应的分区数量,制定消息分配方案,哪个消费者应该消费哪个分区,以确保负载均衡和高效消费。Kafka中的一个partition只会被一个consumer消费。
5.1.2. transaction coordinator
负责事务协调,每个事务型producer都要和transaction coordinator交互
- 确保事务的原子性,即所有消息要不全部写入成功,要不全部不写入
- 处理事务的开始、提交、回滚等操作,确保消息的一致性和可靠性
5.1.2.1. 确保事务性消息的原子性操作的基本原理
- 事务的开始: 生产者启动事务时,它向事务 Coordinator 发送一个事务的起始请求。在这个阶段,事务 Coordinator 会为该事务分配一个唯一的事务 ID。
- 事务性生产: 在事务启动后,生产者可以发送一批消息,并在发送的消息中关联这个事务 ID。这确保了这批消息属于同一个事务。
- 事务的提交: 如果在事务期间一切正常,生产者将向事务 Coordinator 发送提交请求。在接收到提交请求后,事务 Coordinator 将事务的状态设置为提交,并将相关消息持久化到 Kafka 服务器。
- 事务的回滚: 如果在事务期间发生错误或者生产者决定回滚事务,生产者将向事务 Coordinator 发送回滚请求。事务 Coordinator 将事务的状态设置为回滚,并丢弃相关消息。
- 消费者的参与: 消费者也可以参与到事务中,以确保在消费消息时能够参与到相同的事务中,保持消息的一致性。
- 幂等性: Kafka 还支持幂等性生产者,这意味着即使生产者在发送消息时失败,重试时也不会引入重复的消息。这与事务性生产者结合使用,可以提供更强的消息传递保障。
5.2. 选举与切换
5.2.1. Coordinator 的选举过程:
coordinator选举机制确保了当前活跃的coordinator出现故障时,集群能够选举出一个新的coordinator来接管协调工作,从而保证整个系统的高可用性。kafka 2.8版本以下支持通过zookeeper进行选举,2.8版本以上新增了基于Kraft算法的选举机制。
基于zookeeper的Kafka Coordinator选举过程可以概括为以下几个步骤:
- Coordinator的注册
每个Broker启动时,都会先在Zookeeper中注册自己有资格竞选哪些Coordinator。不同的Coordinator有不同的注册路径,如/controller,/admin等。 - 选举触发
当没有活跃的Coordinator时,集群中剩余的Broker会开始发起新一轮的选举程序。常见的触发情况包括: 活跃Coordinator宕机、大多数Broker重启导致原Coordinator失去集群大多数票数等。每个broker会定期向zookeeper发送心跳来证明自己活着,如果长时间没有心跳,zookeeper就认为该broker已经故障。 - 选举过程
所有参与选举的Broker会先在Zookeeper上创建临时节点,节点路径格式为/${COORDINATOR_TYPE}/candidate/control_path_${CONTROL_PATH_VERSION}_${BROKER_ID}-${GENERATED_ID}。 然后各Broker按照节点路径的字典序排列,字典序最小的临时节点所对应的Broker就是被选举为新的Coordinator。 - 胜出通知
被选为新Coordinator的Broker会收到来自Zookeeper的通知,它会创建${COORDINATOR_TYPE}/controller_epoch持久节点,并写入自己的BrokerID和纪元值(epoch),其它Broker发现这个节点后就知道新Coordinator是谁了。 - Coordinator上线
新选举产生的Coordinator会先从Zookeeper获取所需的元数据信息,如分区副本分配方案等。之后它会开始发送请求给各个Broker,接管整个集群的协调工作。
https://developer.aliyun.com/article/1479596
评论