核心:
- 顺序读写
- page cache,避免每次读取磁盘。也正是因为顺序读写,避免了大量page cache miss,可以充分利用page cache。
- 零拷贝。
1. 存储结构
一个topic下多个partition,每个partition使用一个文件夹存储。partition命名规则为:topic名称-序号(从0开始)
一个partion分为多个大小大致相等的segment,kafka的数据清理是以segment为最小单位的,当数据超过最长保存时间或最大保存空间后,会优先释放最早的segment。log.segment.bytes,此配置是指 log 日志划分成块的大小,默认值 1G。
segment命名规则:partion全局的第一个segment从0开始,后续每个segment文件命名为上一个segment文件最后一条消息的offset值+1。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。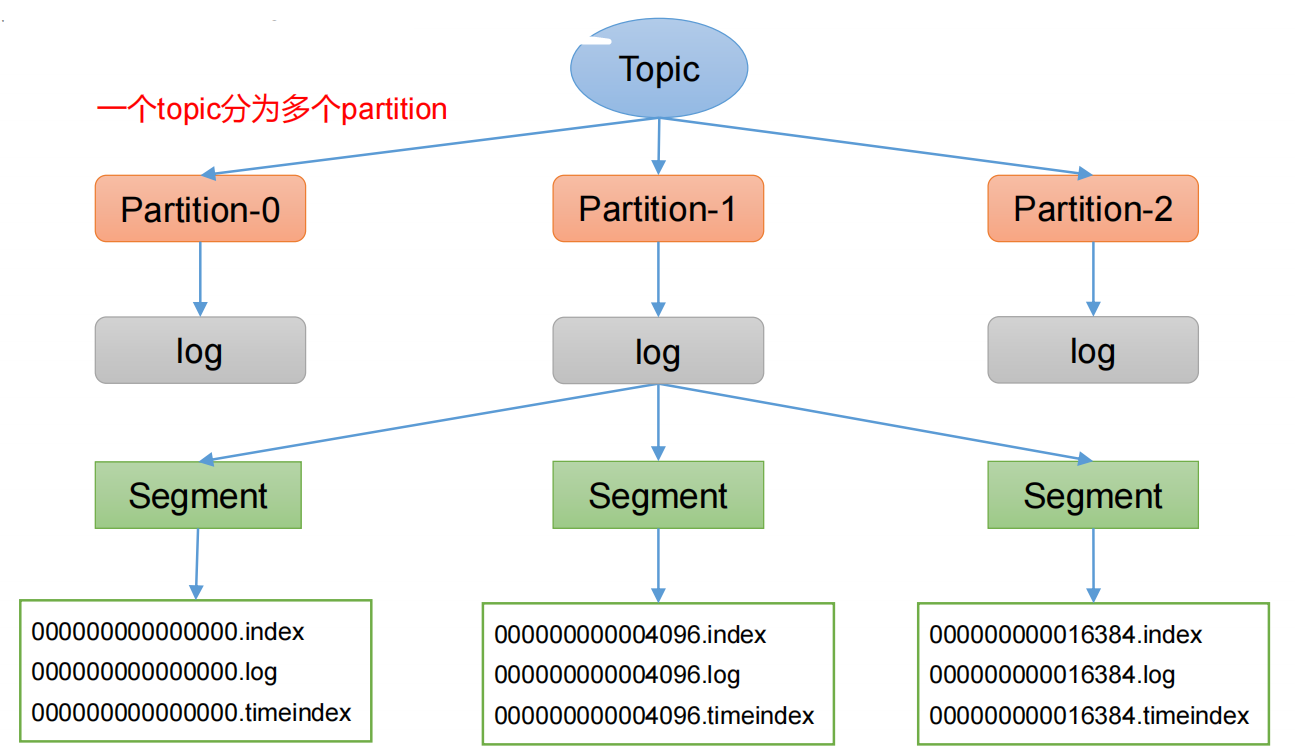
一个segment分为如下三个文件:
- xxx.log文件
- xxx.index文件
- xxx.timeindex文件
2. 稀疏索引
segment index file采取稀疏索引存储方式,不会为每条数据创建索引,大大的减少索了引文件大小。可以通过配置项log.index.interval.bytes控制。稀疏索引间存储数据的大小,默认4kb,kafka每当写入了4kb大小的日志(.log),然后就往index文件里面记录一个索引。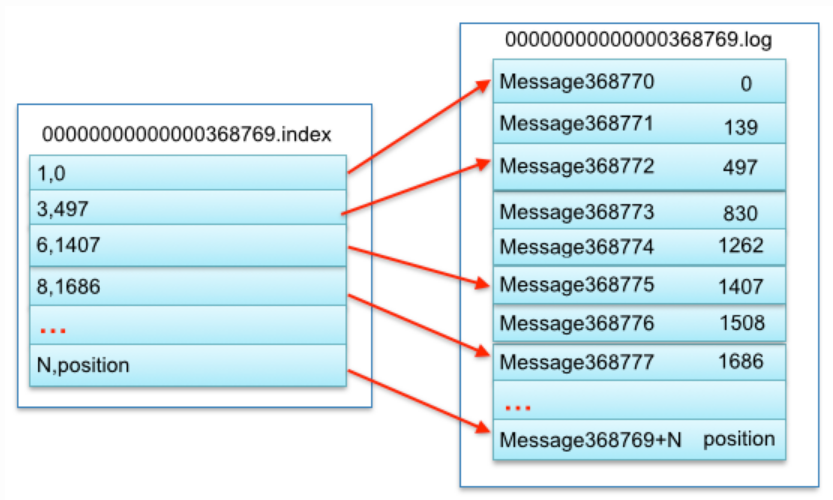
稀疏索引占用空间小,查询相对稠密索引慢;稠密索引占用空间大,查询快
3. 查找过程
根据offset二分查找文件列表,就可以快速定位到具体的.log和.index文件。 如当offset=600时定位到00000000000000000522.index|log文件。在index文件中根据offset来查找到最近的不大于当前查找目标的记录,找到对应的position。索引文件中的position是相对于日志文件(.log 文件)的首地址。position记录了特定offset对应的消息在日志文件中的具体位置,这个位置是从日志文件开头开始计算的偏移量。通过这个相对位置,可以快速在日志文件中定位到对应的消息进行读取操作。通过position快速跳转到log对应位置然后顺序查找到所用的消息。
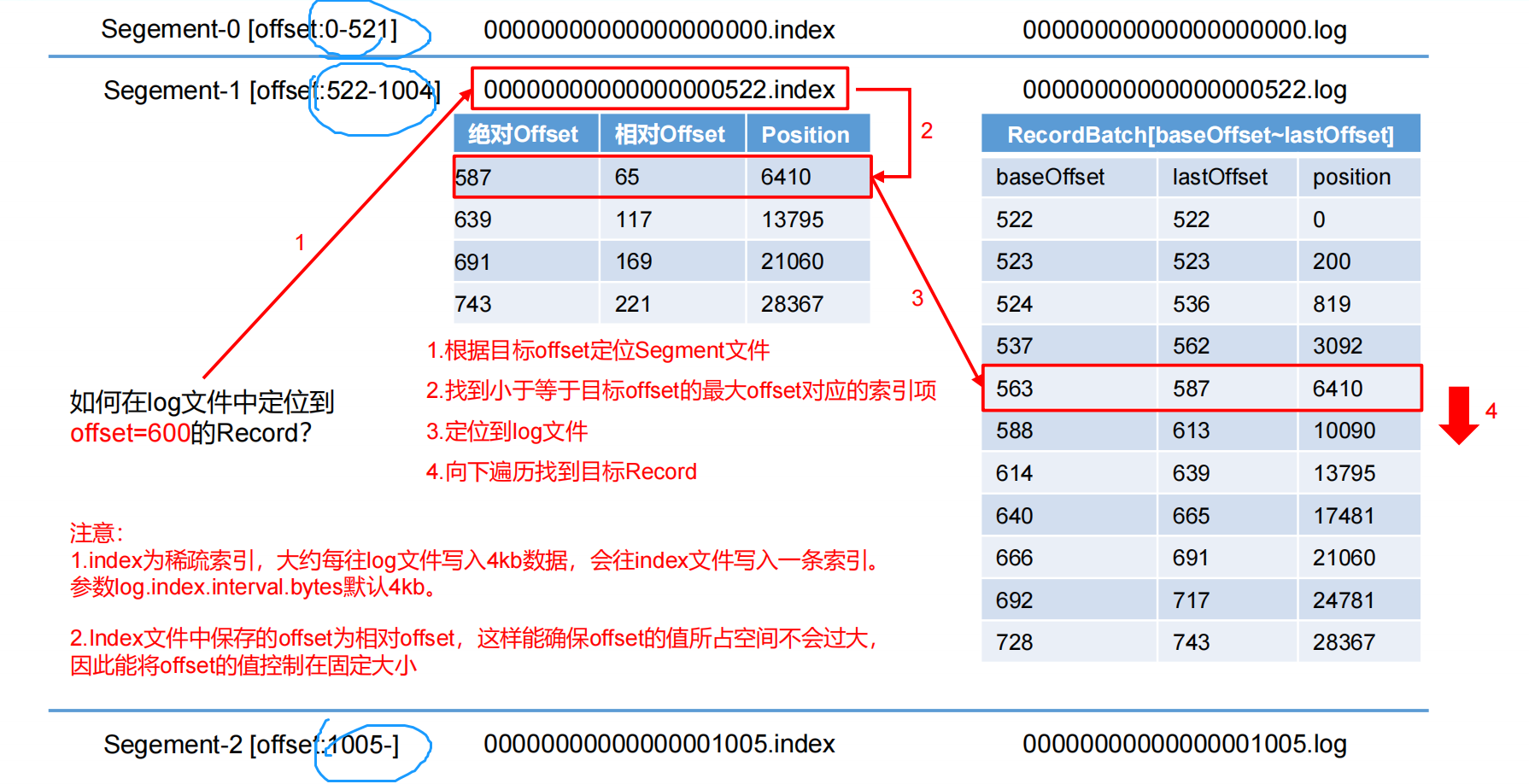
kafka拉数据不是每次都从磁盘上获取的,顺序读的特性可以很好地利用page cache机制,直接从内存中获取数据。
timeindex文件存储的了时间戳和offset的映射关系,主要是用于基与时间戳快速定位消息。采用的也是稀疏索引。
kafka的性能与内存大小有关,内存越大,page cache存储的数据就越多,读写越快。
4. # leader-epoch-checkpoint
在Apache Kafka中,leader-epoch-checkpoint 主要涉及到Leader Epoch机制,这是一种用于管理Kafka集群中分区领导者变更的关键机制,目的是为了简化和增强领导者选举和数据一致性方面的功能。
0 <span class="tag">#版本号</span>
1 <span class="tag">#下面的记录行数</span>
29 2485991681 <span class="tag">#leader</span> epoch ,可以看到有两位值(epoch,offset)。
## epoch表示leader的版本号,从0开始,当leader变更过1次时epoch就会+1
## offset则对应于该epoch版本的leader写入第一条消息的位移
5. 零拷贝
在传统的数据读取和发送方式中,数据从磁盘文件读取到内核缓冲区,再从内核缓冲区复制到用户缓冲区,然后从用户缓冲区再复制到内核的套接字缓冲区(用于网络发送),最后发送到网络。这种多次数据复制会带来大量的 CPU 开销和内存带宽占用,降低了系统性能。
零拷贝(Zero-Copy)是一种I/O 操作优化技术,可以快速高效地将数据从文件系统移动到网络接口,而不需要将其从内核空间复制到用户空间。其在 FTP 或者 HTTP 等协议中可以显著地提升性能。但是需要注意的是,并不是所有的操作系统都支持这一特性,目前只有在使用 NIO 和 Epoll 传输时才可使用该特性。需要注意,它不能用于实现了数据加密或者压缩的文件系统上。零拷贝大大提高了应用程序的性能,减少了内核和用户模式之间的上下文切换 。对 Linux操作系统而言,零拷贝技术依赖于底层的sendfile() 方法实现 。对应于Java 语言,Fi leChannal.transferTo()方法的底层实现就是 sendfile()方法 。
零拷贝技术通过 DMA (Direct Memory Access) 技术将文件内容复制到内核模式下的 Read Buffer 中。零拷贝是针对内核模式而言的, 数据在内核模式下实现了零拷贝。
Kafka 利用了sendfile()系统调用。当 Kafka 的生产者发送消息或者消费者读取消息时,数据可以直接从文件系统缓存(内核缓冲区)通过sendfile()系统调用发送到网络接口(套接字缓冲区),避免了数据从内核缓冲区到用户缓冲区再回到内核缓冲区(套接字缓冲区)的多余复制。例如,假设 Kafka 存储的日志文件(存储消息数据)已经在操作系统的页面缓存(内核缓冲区)中,当需要将数据发送给消费者时,sendfile()直接将页面缓存中的数据传输到网络套接字,减少了数据复制的次数。
6. 思考
kafka中topic的数量是否有上限;partition的数量是否有上限
- 增加broker节点数量
- 增加broker磁盘数量
- 增加内存大小
7. 参考文献
一文彻底弄懂零拷贝原理零拷贝(Zero-Copy)是一种 I/O 操作优化技术,可以快速高效地将数据从文件系统移动到网络 - 掘金 (juejin.cn)
评论