1. 使用方式
pprof必须在代码里引入才能使用,不像Java里jdk工具包中的 jps、jstat、jinfo、jstack、jmap 工具可以单独使用。pprof可以从以下两个包中引入
import "net/http/pprof"
import "github.com/pkg/profile"
Golang pprof的使用方式主要有两种
- 在程序中通过http接口的方式暴露相应的pprof的采集控制界面,需要依赖
net/http/pprof,net/http/pprof使用runtime/pprof包来进行封装。 github.com/pkg/profile可以用来产生dump文件,程序中通过代码开启对应指标的采集样本功能,采集一段时间的样本后生成二进制文件,最后通过go tool pprof命令去对样本的数据进行分析。
1.1. http接口的方式暴露采集控制界面
import (
"net/http"
// 代码里引入 pprof
_ "net/http/pprof"
)
func main() {
// 代码里引入http server
go func() {
if err := http.ListenAndServe(":6060", nil); err != nil {
log.Fatal(err)
}
os.Exit(0)
}()
// 省略业务代码
}
可以通过 http://127.0.0.1:6060 /debug/pprof/来访问 pprof
1.2. 通过代码开启
import (
"github.com/pkg/profile"
"time"
)
func main() {
// 同时启用CPU和内存分析
p := profile.Start(
profile.ProfilePath("./profiles"), // 指定输出目录
profile.CPUProfile, // 启用CPU分析
//profile.MemProfile, // 启用内存分析
//profile.MemProfileRate(4096), // 设置内存分析的采样率
//profile.BlockProfile, // 启用阻塞分析
//profile.MutexProfile, // 启用互斥锁分析
profile.NoShutdownHook, // 禁用自动关闭钩子
)
// 您的程序代码...
// 在适当的时机停止分析
defer p.Stop()
}
使用标准的pkg/profile包时,一次只能激活一种主要的分析类型(CPU或内存或阻塞等)。如果需要同时收集多种类型,需要直接使用底层的runtime/pprof包。tprofile.Start函数签名如下
func Start(options ...func(*Profile)) interface {
Stop()
}
- 函数名Start
- 函数参数为可变长数组,每个元素是一个函数
func(*Profile),入参是*Profile指针,返回值为void - 函数的返回值为内联定义的接口类型,这个接口只有一个方法要求:
Stop(),无入参且不返回值Note可以将Start和Stop方法封装成函数,通过api或信号量的触发的方式调用,实现程序运行的任意时刻触发dump分析
2. 监控指标
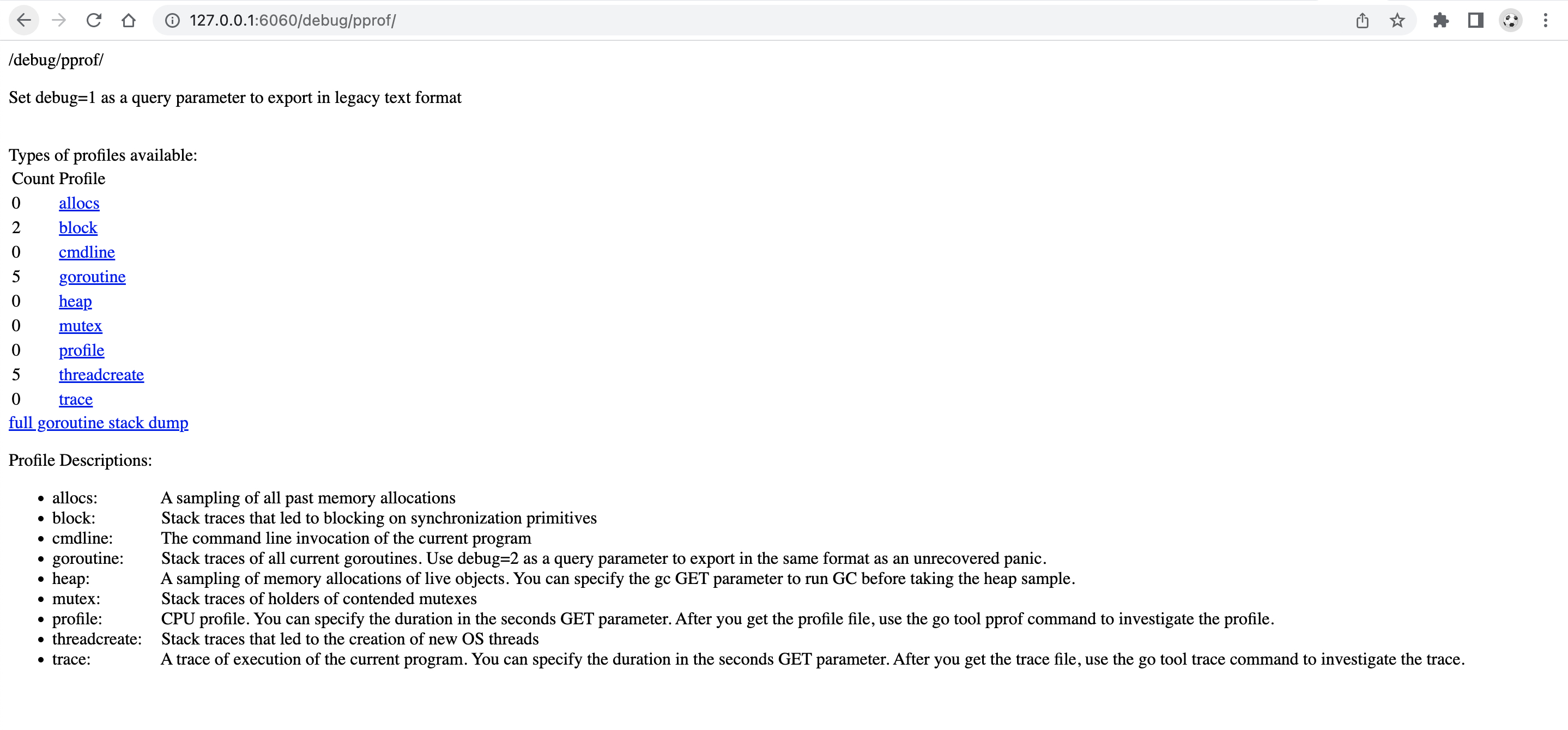
2.1. allocs
作用:内存分配分析,包含哪些函数分配了内存以及分配了多少内存。
使用场景:优化内存分配,分析内存泄露
2.2. blcok
作用:显示导致goroutingz阻塞的操作,如互斥锁、通道操作等
使用场景:发现并解决程序中的并发瓶颈,特别是因锁竞争导致的性能问题
2.3. cmdline
作用:显示启动程序时使用的命令行参数
使用场景:确认程序是以什么参数启动的,对调试特定配置下的问题很有用
2.4. gorouting
作用:显示当前所有gorouting的堆栈
使用场景:查看程序中的所有gorouting的状态,诊断死锁、泄露或其他并发问题
2.5. heap
作用:显示当前堆内存的使用情况,包括哪些对象占用内存及大小
使用场景:查找内存泄露,分析程序中内存占用过高的对象
2.6. mutex
作用:显示互斥锁的竞争情况,包括哪些锁被长时间持有或频繁竞争
使用场景:发现并解决因互斥锁导致的性能瓶颈
2.7. profile
作用:记录cpu使用情况,显示哪些函数占用了最多的cpu时间
使用场景:识别程序中的cpu热点,优化计算密集型函数
当它被激活时,应用程序默认通过SIGPROF信号要求操作系统每10毫秒中断一次。当应用程序收到 SIGPROF 时,它会暂停当前活动并将执行转移到分析器。分析器收集诸如当前 goroutine活动之类的数据,并汇总可以检索的执行统计信息;然后停止分析并继续执行直到下一次的 SIGPROF。默认情况下,访问/debug/pprof/profile地址会执行30秒的 CPU分析。在 30 秒内,我们的应用程序每10毫秒中断一次。使用seconds参数将分析应该持续多长时间传递给路由(例如 /debug/pprof/profile?seconds=15),也可以更改中断率(甚至小于10毫秒)。但多数情况下,10 毫秒应该足够了,再减小这个值(意味着增加频率)时,可能会对性能产生较大影响。30 秒后,就可以下载 CPU 分析器的结果。
在运行benchmark的时候,可以通过命令行增加-cpuprofile参数的方式激活
2.7.1. 结果分析
可以通过go tool pprof cpuprofile/cpu.pprof生成一个交互终端来进行分析。
(base) ➜ cpu go tool pprof cpuprofile/cpu.pprof
Type: cpu
Time: Mar 4, 2024 at 3:14pm (CST)
Duration: 4.35s, Total samples = 200ms ( 4.60%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 200ms, 100% of 200ms total
Showing top 10 nodes out of 16
flat flat% sum% cum cum%
190ms 95.00% 95.00% 190ms 95.00% syscall.syscall
10ms 5.00% 100% 10ms 5.00% runtime.pthread_cond_signal
0 0% 100% 190ms 95.00% internal/poll.(*FD).Write
0 0% 100% 190ms 95.00% internal/poll.ignoringEINTRIO (inline)
0 0% 100% 190ms 95.00% log.(*Logger).output
0 0% 100% 190ms 95.00% log.Println (inline)
0 0% 100% 190ms 95.00% main.busyCpu
0 0% 100% 190ms 95.00% os.(*File).Write
0 0% 100% 190ms 95.00% os.(*File).write (inline)
0 0% 100% 10ms 5.00% runtime.exitsyscallfast.func1。
每个列的含义如下:flat:函数自身的运行耗时(排除了子函数的调用耗时)flat%:flat运行耗时占用总的采集样本的时间和的比例,这里所有节点运行的flat时间和为200ms。sum%:函数自身和其之上的函数运行的flat时间占所有采集样本时间总和的比例。cum:当前函数和其子函数的调用总的运行时间cum%:cum耗时占总的采集样本的时间和的比例。
也可以通过go tool pprof -http=:8082 cpuprofile/cpu.pprof 的方式启动一个webserver进行分析。
当然,也可以选择火焰图的方式进行展示并分析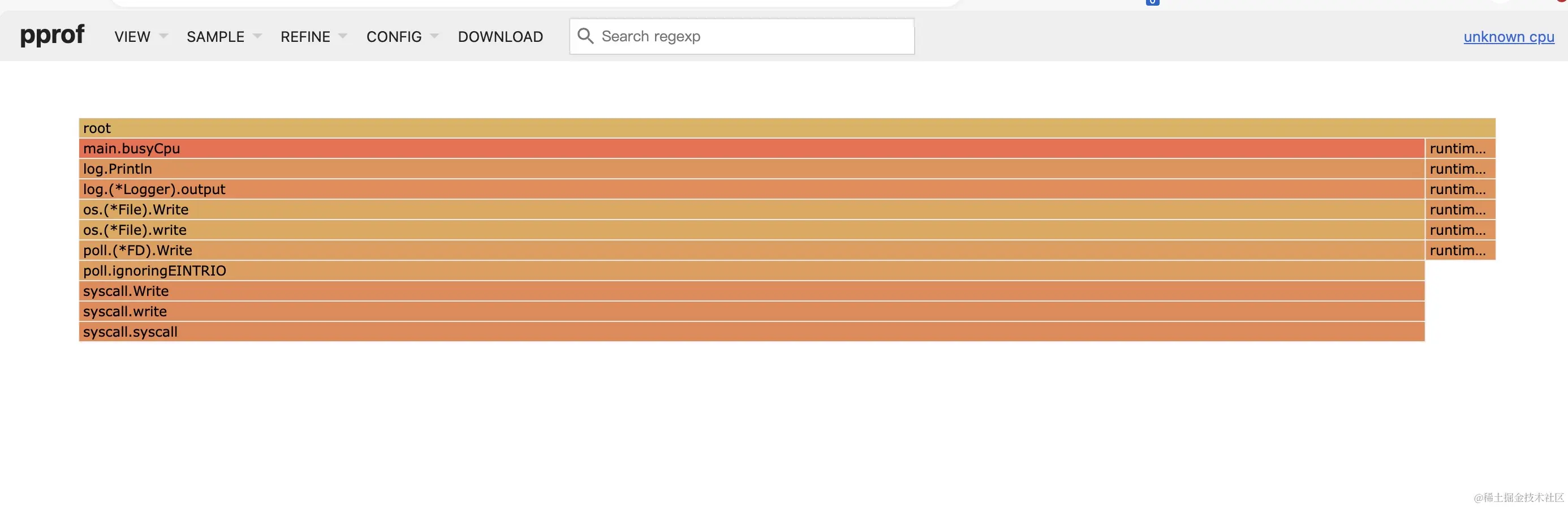
在web界面还可以通过source视图去查看函数节点的耗时以及它的子调用函数中耗时的地方,第一栏时间是flat耗时,第二栏时间是cum耗时。 耗时百分比是cum耗时占样本总和的百分比。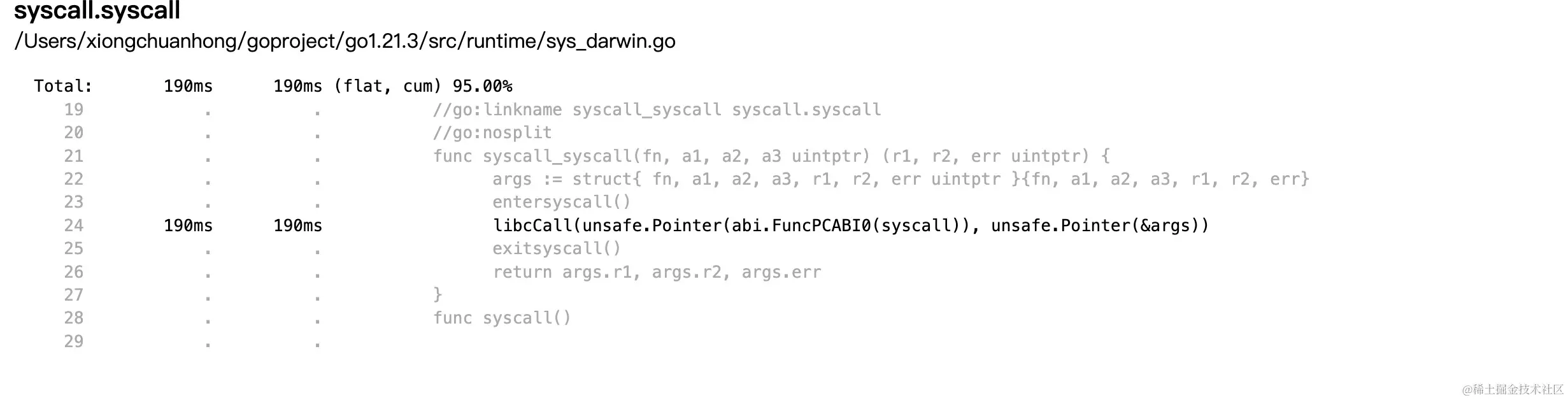
2.8. threadtrace
作用:显示导致创建操作系统线程的堆栈跟踪
使用场景:分析程序中操作系统线程的创建情况,优化系统资源使用
2.9. trace
作用:记录程序执行过程中的详细事件序列
使用场景:全面分析程序行为,包括gorouting的创建、调度和阻塞等细节问题
评论