RAG(Retrieval-Augmented-Generation, 检索增强生成)is a process that helps AI models "look things up" before they answer, like accessing my calender or the weather service. Essentially, RAG is just a type of AI workflow.RAG(中文为检索增强生成) = 检索技术 + LLM Prompt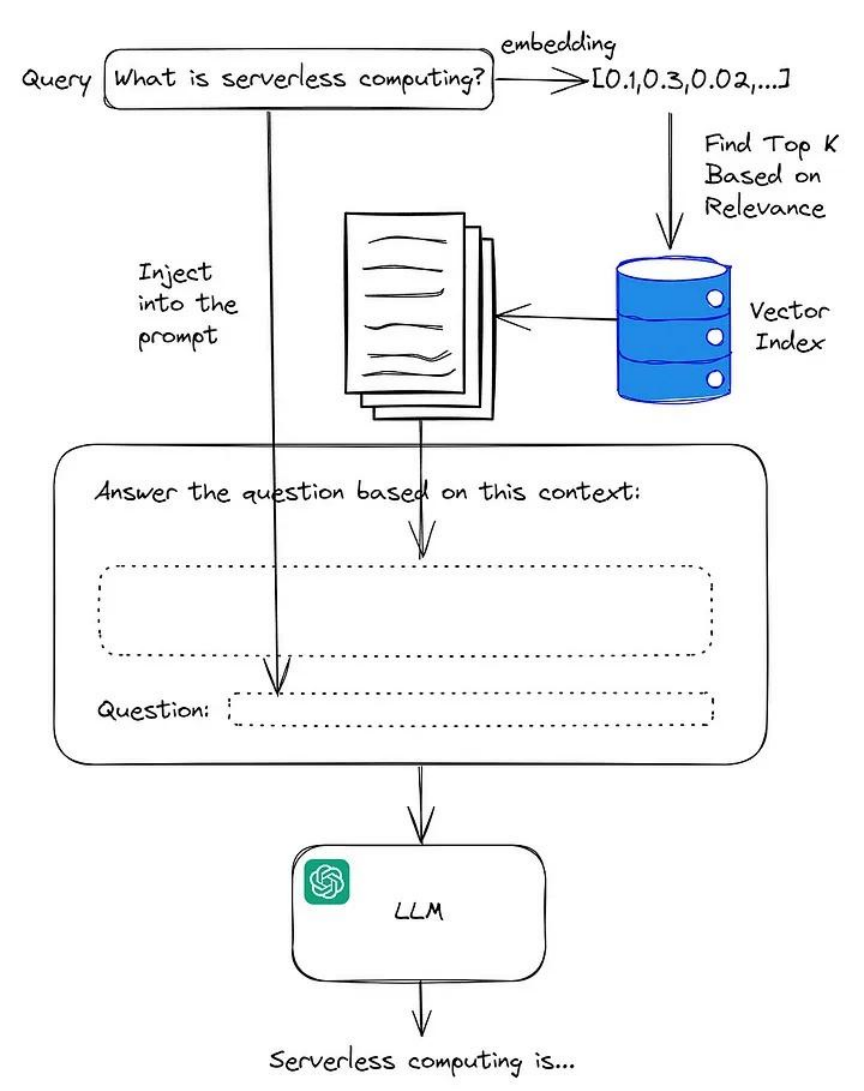
完整的RAG应用流程主要包含两个阶段:
- 数据准备阶段:数据提取——>文本分割——>向量化(embedding)——>数据入库
- 应用阶段:用户提问——>数据检索(召回)——>注入Prompt——>LLM生成答案
1. 数据准备阶段
数据准备一般是一个离线的过程,主要是将私域数据向量化后构建索引并存入数据库的过程。主要包括:数据提取、文本分割、向量化、数据入库等环节。
2. 数据应用阶段
2.1. 数据检索
常见的数据检索方法包括:相似性检索、全文检索等,根据检索效果,一般可以选择多种检索方式融合,提升召回率。
- 相似性检索:即计算查询向量与所有存储向量的相似性得分,返回得分高的记录。常见的相似性计算方法包括:余弦相似性、欧氏距离、曼哈顿距离等。
- 全文检索:全文检索是一种比较经典的检索方式,在数据存入时,通过关键词构建倒排索引;在检索时,通过关键词进行全文检索,找到对应的记录。>)
2.2. prompt注入
Prompt作为大模型的直接输入,是影响模型输出准确率的关键因素之一。在RAG场景中,Prompt一般包括任务描述、背景知识(检索得到)、任务指令(一般是用户提问)等,根据任务场景和大模型性能,也可以在Prompt中适当加入其他指令优化大模型的输出。一个简单知识问答场景的Prompt如下所示:
【任务描述】
假如你是一个专业的客服机器人,请参考【背景知识】,回答【问题】
【背景知识】
{content} // 数据检索得到的相关文本
【问题】
石头扫地机器人P10的续航时间是多久?
Prompt的设计只有方法、没有语法,比较依赖于个人经验,在实际应用过程中,往往需要根据大模型的实际输出进行针对性的Prompt调优。
3. 示例
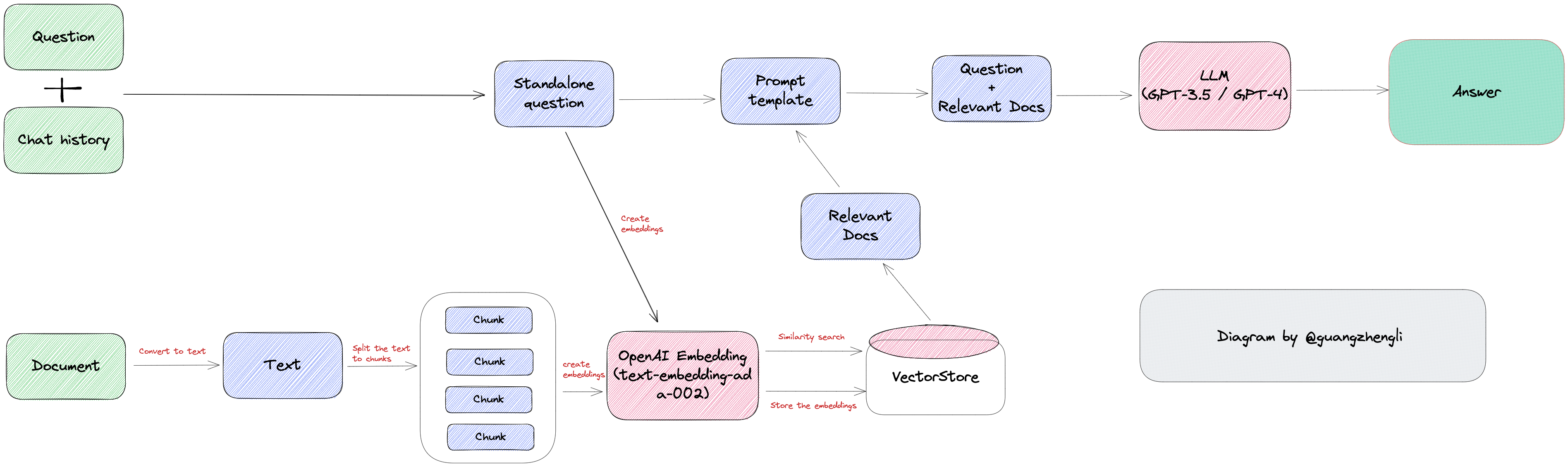
整体的开发流程如上图所示:
- 加载文档,获取目标文本信息。例如 LLM 主流框架 LangChain 中 File Loader 和 Web Loader 的两种文本获取方式。
- 基于文件系统的 File Loader,如加载 PDF 文件、Word 文件等。
- 基于网络的 Web Loader,如某个网页,AWS S3 等。
- 将目标文本拆分为多个段落,拆分方式主要基于两种。
- 一种是基于文字数量的拆分法,例如 1000 字为一段,这种方式的优点是简单,缺点是可能会将一个段落拆分成多个段落,导致段落的连贯性变差,从而导致最终回答结果可能缺少上下文而降低回答质量。
- 另一种是基于标点符号的拆分法,例如以换行为分隔符,这种方式的优点是段落的连贯性好,缺点是每个段落大小不一,可能会导致触发 GPT tokens 的限制。
- 最后一种是基于 GPT tokens 限制的拆分法,例如以 2000 tokens 为一组,最终查询时搜索出最相关的两个段落,这样加到一起也才 4000 tokens,就不会触发到 4096 tokens 的限制。
- 将拆分的文本块统一存入 向量数据库 中。
- 将用户问题转化为向量,然后通过向量数据库进行检索,得到最相关的文本段落。(需要注意的是,这里的检索并不是传统数据库的模糊匹配或者倒排索引,而是基于语义化的搜索能力,所以检索出的文本才能回答用户问题,详细请看另外一篇博客 向量数据库
- 将检索出来的相关文本信息,用户问题和系统的 prompt 三个组合成一个针对于 RAG 场景的 Prompt,例如 Prompt 中明确写到使用参考文本回答问题,而不是 GPT 自己回答。
- GPT 回答最终得到的 Prompt,得到最终的答案。
评论