1. redis支持数据类型
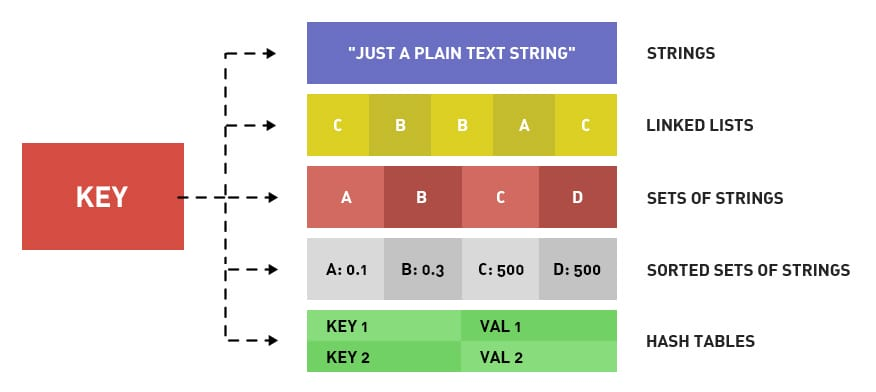
- 字符串
- hash(key-value)
- list(有序列表)
- set(无序唯一集合)
- zset(有序唯一优先级队列,每个元素关联一个分数,按从小到大排列)
- Bitmap
- HyperLogLog,占用内存很小(12kb)的情况,可以用于估算接近2^{64}-1个元素的基数(集合去重后的数量)
- SUBSCRIBE与PUBLISH,发布订阅模型
- stream 消息队列
| 数据结构 | 特点 | 典型应用场景 |
|---|---|---|
| String | 单值存储 | 缓存、计数器、分布式锁 |
| List | 有序队列 | 消息队列、任务调度 |
| Set | 无序不重复 | 用户标签、去重、共同好友 |
| Sorted Set | 有序集合 | 排行榜、延时任务 |
| Hash | 字典结构 | 存储用户信息、购物车 |
| Bitmap | 位操作 | 签到、活跃用户统计 |
| HyperLogLog | 近似去重 | UV 统计、大规模去重 |
| Geo | 地理位置存储 | LBS、附近的人 |
| Stream | 日志队列 | 日志存储、消息队列 |
2. 数据库
Redis本身支持16个数据库(0~15),通过 数据库id 设置,默认为0
2.1. 切换DB
select 0;
select 10;
2.2. 清空当前DB数据
flushdb
# flushdb async
2.3. 清空当DB数据
flushall
flushall async
3. bitmap
Redis Bitmap(位图) 是一种特殊的String 类型数据结构,它的本质是一个二进制数组,支持按位(bit)操作,非常适合用于高效存储和查询二进制状态,例如用户签到、活跃用户统计、设备在线状态等。
在Bitmap中,每个bit 位只能是 0 或 1,可以用来表示 "是/否"、"开/关" 等布尔状态,且 存储效率极高(1 字节可以存储 8 位,1MB可以存储 8,388,608(约 800 万)个用户状态)。
3.1. SETBIT
设置某一位的值,SETBIT key offset value
key:Bitmap 的键offset:要设置的位偏移(索引),从 0 开始value:0或1
SETBIT user:1001:sign 0 1
# 设置第0位为 1
SETBIT user:1001:sign 1 1
# 设置第 1 位为 1
SETBIT user:1001:sign 2 0
# 设置第 2 位为 0
这表示 user:1001 在 第 0 天和第 1 天签到,第 2 天未签到。
3.2. GETBIT
获取某一位的值,GETBIT key offset
key:Bitmap 的键offset:要获取的位偏移(索引)
GETBIT user:1001:sign 0
# 返回 1,表示第 0 天已签到
GETBIT user:1001:sign 2
# 返回 0,表示第 2 天未签到`
3.3. BITCOUNT
统计 Bitmap 中值为1的位,BITCOUNT key [start end],左闭右闭区间
key:Bitmap 的键start、end(可选):字节范围(单位是字节,不是 bit),如果不提供,则统计整个 Bitmap
BITCOUNT user:1001:sign
# 统计该 Bitmap中1的个数
BITCOUNT user:1001:sign 0 1
# 统计前两个字节的1的个数
假设 user:1001:sign 的前 7 位是 1101010,BITCOUNT 返回 4,表示用户这一周签到4天
3.4. BITOP
按位运算(AND、OR、XOR、NOT),BITOP 允许对多个 Bitmap 进行按位操作,并将结果存储到一个新的键中。BITOP operation destkey key1 key2 ...
operation:支持AND(与)、OR(或)、XOR(异或)、NOT(非)destkey:存储计算结果的 Bitmapkey1 key2 ...:参与计算的 Bitmap
# 计算 user1 和 user2 的交集(即两个人都签到的天数)
BITOP AND both_signed user:1001:sign user:1002:sign
# 统计共有多少天都签到
BITCOUNT both_signed
AND(交集):计算 多个用户都签到的天数OR(并集):计算 至少有一个用户签到的天数XOR(异或):计算 只签到了一方的天数NOT(取反):计算 未签到的天数
3.5. BITPOS
查找第一个1或0出现的位置,BITPOS key bit [start end]
bit:要查找的值(0或1)start end(可选):字节范围
# 找到第一个 1 出现的位置
BITPOS user:1001:sign 1
如果 user:1001:sign 是 0001001,那么 BITPOS 返回 3(因为第3位是第一个 1)。
4. stream、发布订阅
✅ 消费者组共享的是整体的消费进度(last-delivered-id),但不同消费者不会共享具体的消费状态。
✅ 一个消息ID只能被组内一个消费者消费,除非未被 XACK确认。
✅ 如果消费者崩溃或超时,其他消费者可以通过 XCLAIM 夺取消息
✅ redis stream不提供类似kafka的多partition机制,多个消费者可以并行消费。如消费者1消费1-100,消费者2消费101-200
| 特性 | Redis Stream | 发布/订阅(Pub/Sub) |
|---|---|---|
| 消息存储 | 持久化存储(可以读取历史消息) | 不存储消息(消息发布后不会被保留) |
| 消息消费 | 多个消费者可以各自独立消费,支持消费组 | 订阅的客户端实时接收消息,消息不会重复投递 |
| 历史数据 | 消费者可以读取之前的消息 | 只能接收发布后的新消息 |
| 消息确认 | 消费者需要手动确认消费 | 没有消息确认机制 |
| 消费模式 | 支持点对点(多个消费者不同分配消息)和广播 | 纯粹的广播模式 |
| 持久化 | 支持持久化(基于 AOF 或 RDB 机制) | 不支持持久化 |
| 典型应用场景 | 日志收集、事件溯源、任务队列 | 实时通知、事件广播 |
4.1. redis id递增
reids id的设计考虑了时间回拨的情况,为了保证消息是有序的,因此Redis生成的ID是单调递增有序的。由于ID中包含时间戳部分,为了避免服务器时间错误而带来的问题(例如服务器时间延后了),Redis的每个Stream类型数据都维护一个latest_generated_id属性,用于记录最后一个消息的ID。若发现当前时间戳退后(小于latest_generated_id所记录的),则采用时间戳不变而序号递增的方案来作为新消息ID(这也是序号为什么使用int64的原因,保证有足够多的的序号),从而保证ID的单调递增性质。
5. 查找所有key
5.1. scan系列命令
# 分页查找所有key
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]
示例
2025-03-13 23:27:05 set name w
OK
2025-03-13 23:27:11 set age 19
OK
2025-03-13 23:31:32 FLUSHDB
OK
2025-03-13 23:31:38 set name shineri
OK
2025-03-13 23:31:43 set name shinerio
OK
2025-03-13 23:31:48 set age 30
OK
2025-03-13 23:31:53 set address beijing
OK
2025-03-13 23:34:15 hset person jack 20 alice 30
2
2025-03-13 23:34:39 sadd student jack tom mary
3
2025-03-13 23:35:46 zadd teach 1 xiaohong
1
2025-03-13 23:35:54 zadd teach 10 xiaolan
1
2025-03-13 23:36:09 scan 0 count 10
1) "0"
2) 1) "age"
1) "teach"
2) "name"
3) "student"
4) "address"
5) "person"
2025-03-13 23:37:57 scan 0 match a* count 10
1) "0"
2) 1) "age"
1) "address"
2025-03-13 23:38:49 scan 0 match *s* count 10 type string
1) "0"
2025-03-13 23:41:01 zscan teach 0
1) "0"
2) 1) "xiaohong"
1) "1"
2) "xiaolan"
3) "10"
3) ) "address"
2025-03-13 23:39:29 hscan person 0 count 10
1) "0"
2) 1) "jack"
1) "20"
2) "alice"
2025-03-13 23:40:38 sscan student 0
1) "0"
2) 1) "mary"
1) "tom"
2) "jack"
5.2. scan与smembers
| 对比项 | SMEMBERS |
SCAN |
|---|---|---|
| 返回方式 | 一次性返回所有数据 | 迭代返回,分批获取 |
| 适用场景 | 小集合(几千个以内) | 大集合(百万/千万级) |
| 是否阻塞 | 阻塞(影响 Redis 其他操作) | 非阻塞(分批遍历,不影响 Redis) |
| 查询效率 | 快速获取小集合数据 | 适合大集合,减少网络传输开销 |
| 数据一致性 | 数据不会变化(快照) | 可能在迭代过程中数据发生变化 |
| 支持模式匹配 | ❌ 不支持 | ✅ MATCH pattern |
| 可能返回重复数据 | ❌ 不会 | ✅ 可能,需要去重 |
| COUNT 控制返回量 | ❌ 不支持 | ✅ 支持 COUNT(但不保证精确数量) |
5.3. 什么时候用 SMEMBERS,什么时候用 SCAN?
- ✅ 集合很小(< 10,000) 👉
SMEMBERS一次性获取。 - ✅ 集合很大(> 10,000) 👉 用
SCAN分批遍历,防止阻塞。 - ✅ 需要模式匹配(
MATCH) 👉 用SCAN(SMEMBERS不支持MATCH)。 - ✅ 不希望有重复数据,想一次拿全量数据 👉 用
SMEMBERS(SCAN可能会返回重复项)。
5.4. 总结
SMEMBERS适合小集合,但大集合慎用,否则会阻塞 Redis。SCAN适合大集合,但可能返回重复数据,需要自己去重。- 如果集合元素少于 1 万,可以放心用
SMEMBERS;超过 1 万,建议用SCAN逐步遍历。
评论