1. pipeline
Redis执行一条命令需要经历以下过程:发送命令、命令排队、命令执行、结果响应。由于Redis本身是基于Request/Response协议(停等机制)的,虽然Redis已经提供了像 mget 、mset 这种批量的命令,但是如果某些操作根本就不支持或没有批量的操作或者需要连续执行好几个不同命令,那我们就只能一条一条地执行命令,每执行一条命令都要消耗请求与响应的时间,性能就会大大损耗。Redis中通过Pipeline机制能改善上面这类问题,它能将一组Redis 命令进行组装,通过一次传输给 Redis 并返回结果集。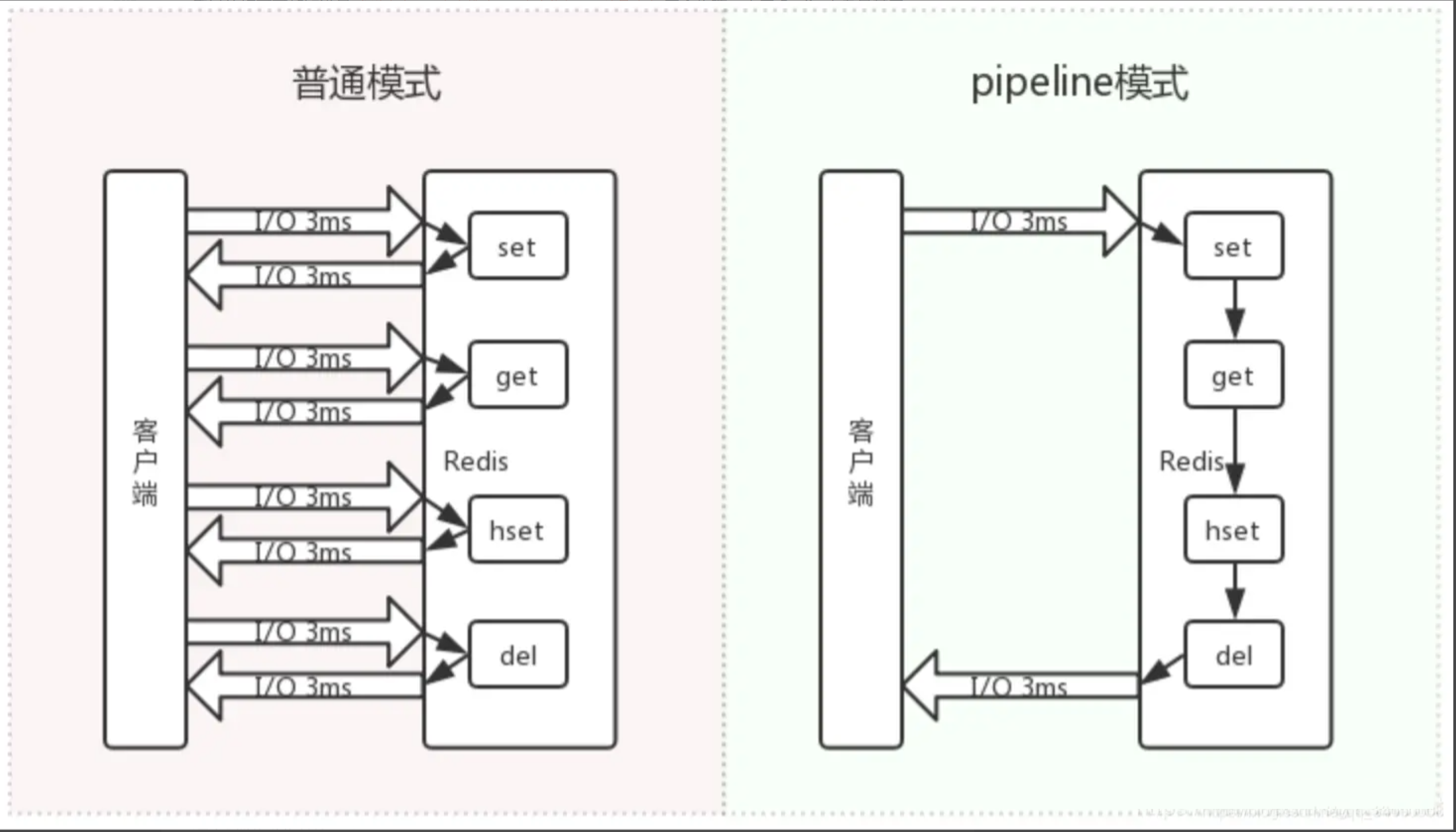
pipeline的方式相对于非pipeline的方式在执行多条命令的情况下性能会显著提升,网络环境越差,执行命令数量越多,提升越大,可以通过如下测试查看
import redis
import time
r = redis.from_url("redis://default:tlq8mzql@dbconn.sealoshzh.site:41787")
pipe = r.pipeline()
start = int(1000 * time.time())
for i in range(0, 10000):
pipe.set('key1', 'value1')
results = pipe.execute()
print("time: %dms" % (int(1000 * time.time()) - start))
start = int(1000 * time.time())
for i in range(0, 10000):
r.execute_command("set key1 value1")
print("time: %dms" % (int(1000 * time.time()) - start))
> time: 126ms
> time: 43839ms
Pipeline是非原子的,Redis实际上还是一条一条的执行的,而执行命令是需要排队执行的,所以就会出现原子性问题。Pipeline中包含的命令不要包含过多Pipeline每次只能作用在一个 Redis 节点上,redis集群化部署的时候,需要确保pipeline中执行的所有命令的key相同,或者将不同的key按照所属redis node拆分到不同的pipeline中
2. 原子性
先说结论,redis的原子性仅保证批量执行当前命令的时候,不会有其他任务或线程能够执行redis命令,也就是保证了不会并发,但是如果执行多个命令,其中部分命令失败不会触发回滚,也不会影响后续的命令的执行。
redis原子执行命令有两种方式:1. multi+exec 2. lua脚本
2.1. multi + exec
2.1.1. 语法错误
test-db-redis.ns-t5f2m76w.svc:6379> multi
OK
test-db-redis.ns-t5f2m76w.svc:6379(TX)> set name shinerio
QUEUED
test-db-redis.ns-t5f2m76w.svc:6379(TX)> error_commnd
(error) ERR unknown command 'error_commnd', with args beginning with:
test-db-redis.ns-t5f2m76w.svc:6379(TX)> set age 30
QUEUED
test-db-redis.ns-t5f2m76w.svc:6379(TX)> exec
(error) EXECABORT Transaction discarded because of previous errors.
test-db-redis.ns-t5f2m76w.svc:6379> get name
(nil)
test-db-redis.ns-t5f2m76w.svc:6379> get age
(nil)
error_command不是一个合法命令,在命令入队时就会立刻提示,使用exec执行命令会直接报错,任何命令都不会生效
2.1.2. 运行时错误
test-db-redis.ns-t5f2m76w.svc:6379> multi
OK
test-db-redis.ns-t5f2m76w.svc:6379(TX)> set name shinerio
QUEUED
test-db-redis.ns-t5f2m76w.svc:6379(TX)> lpush name shinerio1 shinerio2
QUEUED
test-db-redis.ns-t5f2m76w.svc:6379(TX)> set age 30
QUEUED
test-db-redis.ns-t5f2m76w.svc:6379(TX)> exec
1) OK
2) (error) WRONGTYPE Operation against a key holding the wrong kind of value
3) OK
test-db-redis.ns-t5f2m76w.svc:6379> get name
"shinerio"
test-db-redis.ns-t5f2m76w.svc:6379> get age
"30"
运行错误是指输入的指令格式正确,但是在命令执行期间出现的错误,典型场景是当输入参数的数据类型不符合命令的参数要求时,就会发生运行错误。例如下面的例子中,对一个string类型的值执行列表的操作,就会报错。但是除执行中出现错误的命令外,其他命令都能正常执行。
通过分析我们知道了redis中的事务是不满足原子性的,在运行错误的情况下,并没有提供类似数据库中的回滚功能。那么为什么redis不支持回滚呢,官方文档给出了说明,大意如下:
- redis命令失败只会发生在语法错误或数据类型错误的情况,这一结果都是由编程过程中的错误导致,这种情况应该在开发环境中检测出来,而不是生产环境
- 不使用回滚,能使redis内部设计更简单,速度更快
- 回滚不能避免编程逻辑中的错误,如果想要将一个键的值增加2却只增加了1,这种情况即使提供回滚也无法提供帮助
2.2. lua
最常用的EVAL用于执行一段脚本,它的命令的格式如下:
EVAL script numkeys key [key ...] arg [arg ...]
简单解释一下其中的参数:
- script是一段lua脚本程序
- numkeys指定后续参数有几个key,如没有key则为0
- key [key …]表示脚本中用到的redis中的键,在lua脚本中通过KEYS[i]的形式获取
- arg [arg …]表示附加参数,在lua脚本中通过ARGV[i]获取
看一个简单的例子:
127.0.0.1:6379> eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 value1 vauel2
1) "key1"
2) "key2"
3) "value1"
4) "vauel2"
在上面的命令中,双引号中是lua脚本程序,后面的2表示存在两个key,分别是key1和key2,之后的参数是附加参数value1和value2。
如果想要使用lua脚本执行set命令,可以写成这样:
127.0.0.1:6379> EVAL "redis.call('SET', KEYS[1], ARGV[1]);" 1 name Hydra
(nil)
这里使用了redis内置的lua函数redis.call来完成set命令,这里打印的执行结果nil是因为没有返回值,如果不习惯的话,其实我们可以在脚本中添加return 0;的返回语句。
2.2.1. SCRIPT LOAD 和 EVALSHA命令
这两个命令放在一起是因为它们一般成对使用。先看SCRIPT LOAD,它用于把脚本加载到缓存中,返回SHA1校验和,这时候只是缓存了命令,但是命令没有被马上执行,看一个例子:
127.0.0.1:6379> SCRIPT LOAD "return redis.call('GET', KEYS[1]);"
"228d85f44a89b14a5cdb768a29c4c4d907133f56"
这里返回了一个SHA1的校验和,接下来就可以使用EVALSHA来执行脚本了:
127.0.0.1:6379> EVALSHA "228d85f44a89b14a5cdb768a29c4c4d907133f56" 1 name
"shinerio"
这里使用这个SHA1值就相当于导入了上面缓存的命令,在之后再拼接numkeys、key、arg等参数,命令就能够正常执行了。
2.2.2. 其他命令
使用SCRIPT EXISTS命令判断脚本是否被缓存:
127.0.0.1:6379> SCRIPT EXISTS 228d85f44a89b14a5cdb768a29c4c4d907133f56
1) (integer) 1
使用SCRIPT FLUSH命令清除redis中的lua脚本缓存:
127.0.0.1:6379> SCRIPT FLUSH
OK
127.0.0.1:6379> SCRIPT EXISTS 228d85f44a89b14a5cdb768a29c4c4d907133f56
1) (integer) 0
可以看到,执行了SCRIPT FLUSH后,再次通过SHA1值查看脚本时已经不存在。最后,还可以使用SCRIPT KILL命令杀死当前正在运行的 lua 脚本,但是只有当脚本没有执行写操作时才会生效。
从这些操作看来,lua脚本具有下面的优点:
- 多次网络请求可以在一次请求中完成,减少网络开销,减少了网络延迟
- 客户端发送的脚本会存在redis中,其他客户端可以复用这一脚本,而不需要再重复编码完成相同的逻辑
2.2.3. Java代码中使用lua脚本
在Java代码中可以使用Jedis中封装好的API来执行lua脚本,下面是一个使用Jedis执行lua脚本的例子:
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
String script="redis.call('SET', KEYS[1], ARGV[1]);"
+"return redis.call('GET', KEYS[1]);";
List<String> keys= Arrays.asList("age");
List<String> values= Arrays.asList("eighteen");
Object result = jedis.eval(script, keys, values);
System.out.println(result);
}
执行上面的代码,控制台打印了get命令返回的结果:
eighteen
简单的铺垫完成后,我们来看一下lua脚本究竟能否实现回滚级别的原子性。对上面的代码进行改造,插入一条运行错误的命令:
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
String script="redis.call('SET', KEYS[1], ARGV[1]);"
+"redis.call('INCR', KEYS[1]);"
+"return redis.call('GET', KEYS[1]);";
List<String> keys= Arrays.asList("age");
List<String> values= Arrays.asList("eighteen");
Object result = jedis.eval(script, keys, values);
System.out.println(result);
}
查看执行结果: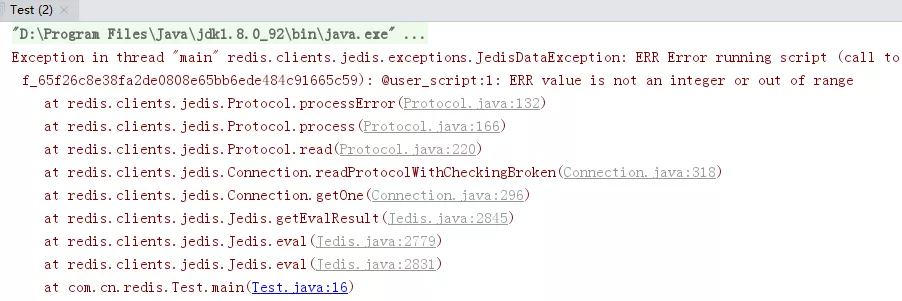
再到客户端执行一下get命令:
127.0.0.1:6379> get age
"eighteen"
也就是说,虽然程序抛出了异常,但异常前的命令还是被正常的执行了且没有被回滚。再试试直接在redis客户端中运行这条指令:
test-db-redis.ns-t5f2m76w.svc:6379> eval "redis.call('SET', KEYS[1], ARGV[1]);redis.call('INCR', KEYS[1]);redis.call('SET', KEYS[2], ARGV[2])" 2 name age shinerio1 31
(error) ERR value is not an integer or out of range script: c0a1a8d54c17320de3688942a347d37d79b34ca7, on @user_script:1.
test-db-redis.ns-t5f2m76w.svc:6379> get name
"shinerio1"
test-db-redis.ns-t5f2m76w.svc:6379> get age
(nil)
同样,错误之前的指令仍然没有被回滚,在redis中是使用的同一个lua解释器来执行所有命令,也就保证了当一段lua脚本在执行时,不会有其他脚本或redis命令同时执行,保证了操作不会被其他指令插入或打扰,实现的仅仅是这种程度上的原子操作。遗憾的是,如果lua脚本运行时出错并中途结束,之后的操作不会进行,之前已经发生的写操作也不会撤销,所以即使使用了lua脚本,也不能实现类似数据库回滚的原子性。
3. redis消费组
Redis会将流中的消息动态分配给消费者组中的各个消费者,确保每条消息只被一个消费者处理。消费者处理完消息后需要显式确认(XACK 命令),Redis 会记录每个消息的处理状态。
分配算法:
- Redis 使用"先到先得"原则,消费者通过XREADGROUP命令主动获取新消息
- 获取消息时,Redis 会将尚未分配给其他消费者的消息分配给请求的消费者
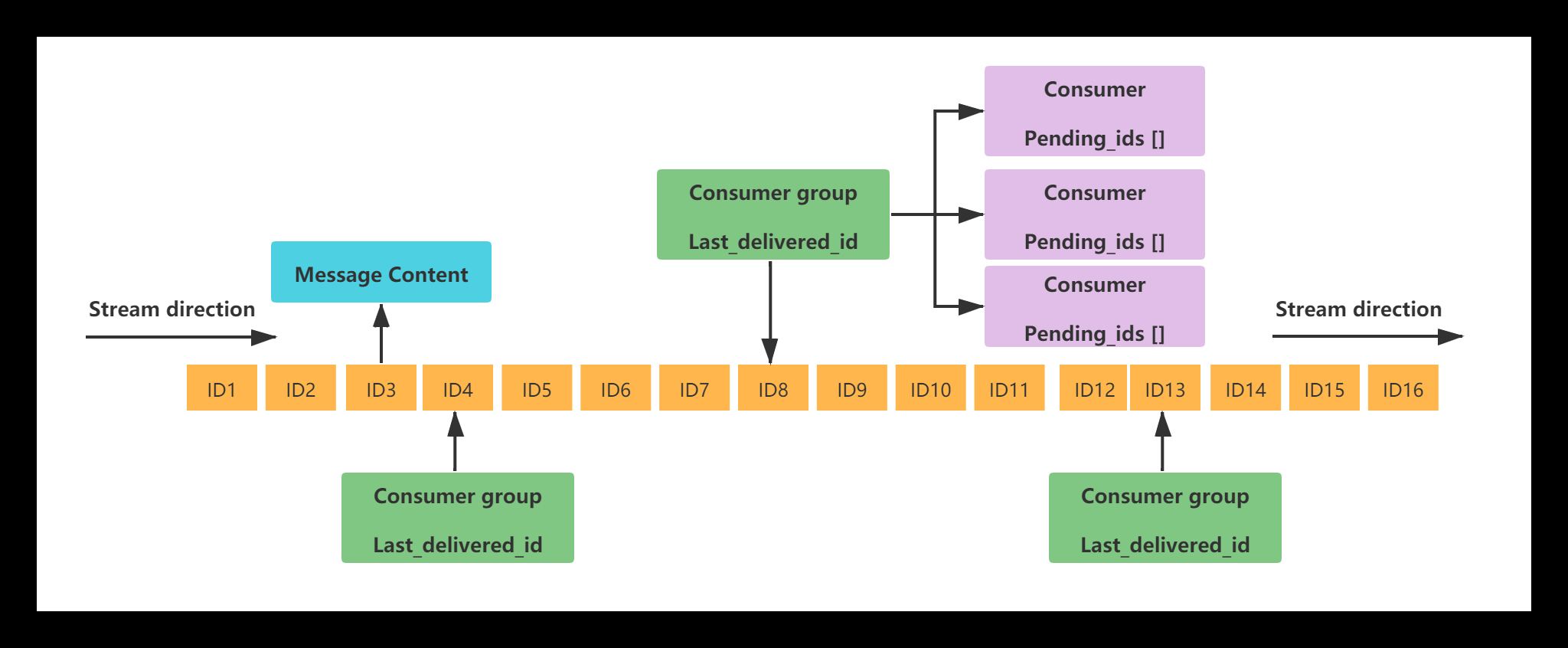
- 每个Redis Stream都有唯一的名称 ,对应唯一的Redis Key 。
- 同一个Stream可以挂载多个消费组ConsumerGroup , 消费组不能自动创建,需要使用XGROUP CREATE命令创建。
- 每个消费组会有个游标 last_delivered_id,任意一个消费者读取了(无需ack)消息都会使游标 last_delivered_id往前移动 ,标识当前消费组消费到哪条消息了。
- 消费组ConsumerGroup同样可以挂载多个消费者Consumer , 每个Consumer并行的读取消息,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。
- 消费者内部有一个属性pending_ids , 记录了当前消费者读取但没有回复ACK的消息ID列表 。Note
redis没有kafka那种partition局部保序的能力,应用程序可以自行创建多个stream实现。
3.1. 核心命令
3.1.1. 添加消息
xadd key [NOMKSTREAM] [MAXLEN|MINID [=|~] threshold [LIMIT count]] *|id field value [field value ...]
- key:redis stream名称
- NOMKSTREAM:当流不存在时,阻止自动创建流。如果流不存在,命令会返回
(nil)。 - MAXLEN:限制流的最大消息数量,超出时自动删除旧消息
- "=" 精确截断,严格保持消息数量不超过阈值
- "~" 近似截断(推荐),允许少量超过阈值以提高性能。
- threshold:阈值
LIMIT count:限制每次删除的最大消息数(Redis 6.2+)。*|id:自定义id,必须大于流中已有最大 ID,否则会报错;自动生成,格式为<毫秒时间戳>-<序列号>(推荐)
MINID: 删除 ID 小于指定值的消息,保留较新的消息field value [field value ...]: 消息的字段和值,类似哈希表结构。
xadd mystream MAXLEN ~ 1000 * name "Eve" age 25 city "London"
此命令添加了一条包含多个字段的消息
python代码读取stream示例如下
import redis
import time
# 连接 Redis
r = redis.Redis(host='localhost', port=6379, db=0)
stream_key = 'mystream'
# 初始 ID 设为 0,表示从第一条消息开始获取
last_id = '0'
while True:
# 阻塞读取,timeout=0 表示永久阻塞,直到有新消息
messages = r.xread({stream_key: last_id}, count=10, block=5000)
if not messages:
print("没有新消息,继续等待...")
continue
# 处理消息
for stream, entries in messages:
for message_id, fields in entries:
print(f"收到消息 ID: {message_id}, 内容: {fields}")
# 更新 last_id 为当前消息的 ID,下次从下一条消息开始获取
last_id = message_id
# 模拟处理耗时
time.sleep(0.1)
输出如下
收到消息 ID: b'1746885666676-0', 内容: {b'name': b'Eve', b'age': b'25', b'city': b'London'}
3.1.2. 获取指定消息列表
xrange key start end [COUNT count]
- start :开始值, - 表示最小值
- end :结束值, + 表示最大值
- count :数量
xrange mystream - +
1) 1) "1746885666676-0"
2) 1) "name"
2) "Eve"
3) "age"
4) "25"
5) "city"
6) "London"
3.1.3. XREAD 以阻塞/非阻塞方式获取消息列表
xread [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]
- count :数量
- milliseconds :可选,阻塞毫秒数,没有设置就是非阻塞模式
- key :队列名
- id :id大于指定消息ID的消息才会被读取
127.0.0.1:6379> XREAD block 1000 streams mystream $
(nil)
(1.07s)
使用 Block 模式,配合$作为ID ,表示读取最新的消息,若没有消息,命令阻塞;等待过程中,其他客户端向队列追加消息,则会立即读取到。因此,典型的队列就是XADD配合 XREAD Block完成。XADD负责生成消息,XREAD负责消费消息。
xread streams mystream 0-0
1) 1) "mystream"
2) 1) 1) "1746885666676-0"
2) 1) "name"
2) "Eve"
3) "age"
4) "25"
5) "city"
6) "London"
2) 1) "1746886506263-0"
2) 1) "name"
2) "Shinerio"
3) "age"
4) "30"
5) "city"
3.1.4. 创建消费者组
XGROUP CREATE key groupname id|$ [MKSTREAM] [ENTRIESREAD entries_read]
id|$: 指定消费者组的起始消费位置。$:从流的末尾开始消费,只处理创建组之后新添加的消息。id:指定具体的消息 ID,从该 ID 之后开始消费(不包含该 ID 本身)。例如:0表示从流的第一条消息开始消费;1620000000000-0表示从指定 ID 之后开始。
MKSTREAM:如果流不存在,则自动创建流、ENTRIESREAD entries_read(可选,Redis 6.2+):记录消费者组创建时流的历史消息数量(仅用于统计,不影响消费行为)。
XGROUP CREATE mystream mygroup 0-0
3.1.5. 从消费者组读取消息
xreadgroup GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] id [id ...]
group:消费者组名称(需提前用XGROUP CREATE创建)。consumer:当前消费者的唯一标识(可动态创建)。key:流的名称。id:起始 ID,控制从何处开始读取:>:只获取从未分配给其他消费者的新消息(推荐)。ID:处理特定ID之后的消息(包括未确认的历史消息)。例如:0表示处理所有待处理消息(包括历史遗留)。
3.1.5.1. NOACK行为
默认行为(无 NOACK),工作流程:
- 读取消息:使用
XREADGROUP读取消息时,Redis 会自动将消息标记为「已分配」(状态为 Pending)。 - 处理消息:消费者处理消息。
- 手动确认:处理完成后,必须显式调用
XACK命令确认消息,将其从 PEL(Pending Entries List)中移除。
使用NOACK选项,工作流程 - 读取消息:使用
XREADGROUP NOACK读取消息时,Redis不会将消息标记为 Pending。 - 处理消息:消费者处理消息。
- 无需手动确认:系统会假设消息已被即时处理,无需后续确认
核心区别对比
| 对比项 | 默认行为(无 NOACK) |
使用 NOACK |
|---|---|---|
| 消息是否自动进入 PEL | 是,读取后立即进入 PEL(状态为 Pending) | 否,需手动 XACK 才会记录到历史 |
| 未确认消息的处理 | 留在 PEL 中,可能被重新分配给其他消费者 | 消息状态不变,不会被重新分配(除非手动 XCLAIM) |
| 典型场景 | 需要可靠消费,确保消息至少被处理一次 | 1. 处理非关键性数据,可以接受偶尔的消息丢失 2. 追求更高的处理性能,减少确认带来的开销 3. 实现"至多一次"传递语义而非"至少一次" |
3.1.6. XACK 消息消费确认
每一个消息都需要单独ack
xack key group id [id ...]
3.1.7. XTRIM 限制Stream长度
xtrim key MAXLEN|MINID [=|~] threshold [LIMIT count]
对stream消息进行淘汰,暴露最近的threashold个消息
- MAXLEN:按消息长度淘汰
- MINID:按最小消息ID淘汰
3.1.8. 删除消费者组
XGROUP DELCONSUMER key groupname consumername
3.1.9. 查看指定stream所有消费者组
XINFO GROUPS mystream
1) 1) "name"
2) "mygroup"
3) "consumers"
4) (integer) 1
5) "pending"
6) (integer) 3
7) "last-delivered-id"
8) "1746886620493-0"
9) "entries-read"
2) (integer) 3
3) "lag"
4) (integer) 0
| 指标 | 值 | 含义 |
|---|---|---|
name |
"mygroup" |
消费者组的名称。 |
consumers |
(integer) 1 |
该消费者组当前有1个活跃的消费者。 |
pending |
(integer) 3 |
待处理消息的数量(即 PEL 中已分配但未确认的消息)。 |
last-delivered-id |
"1746886620493-0" |
最后一次分配给该组的消息 ID,标志着消费进度。 |
entries-read |
(integer) 3 |
该组从流中读取的消息总数(自组创建以来)。 |
lag |
(integer) 0 |
未被该组消费的消息数量(lag = 流总长度 - entries-read)。 |
test-db-redis.ns-12pvbug6.svc:6379> XACK mystream mygroup 1746886620493-0
(integer) 1
test-db-redis.ns-12pvbug6.svc:6379> XINFO GROUPS mystream
1) 1) "name"
2) "mygroup"
3) "consumers"
4) (integer) 1
5) "pending"
6) (integer) 2
7) "last-delivered-id"
8) "1746886620493-0"
9) "entries-read"
2) (integer) 3
3) "lag"
4) (integer) 0
3.1.10. 故障检测
Redis通过消费者组的维护机制来检测故障消费者并重新分配pending消息,Redis Stream没有自动的消费者故障检测机制,而是通过以下方式处理:
- 空闲时间检查
- Redis记录每个消费者的最后活动时间
- 应用程序负责主动检查长时间不活跃的消费者
- 手动声明故障
- 系统中通常需要有监控组件来检测消费者状态
- 发现消费者故障后,需要手动声明该消费者已经失效
3.1.10.1. 重新分配pending消息的方法
- 使用XPENDING命令查看未确认消息
XPENDING mystream mygroup [start-id end-id count [consumer-name]]- 查看消费者组中所有未确认的消息
- 可以筛选特定消费者的未确认消息
每个Pending的消息有4个属性:
- 消息ID
- 所属消费者
- IDLE,已读取时长
- delivery counter,消息被读取次数
- 使用XCLAIM重新分配消息
XCLAIM mystream mygroup new-consumer-name min-idle-time ID1 [ID2 ...]- 将已被分配但未确认的消息转移给新的消费者
min-idle-time参数指定消息必须处于未确认状态的最小时长,只有超过这个时长,才能被转移
- 使用XAUTOCLAIM自动认领消息(Redis 6.2+)
XAUTOCLAIM mystream mygroup new-consumer-name min-idle-time start-id [COUNT count]- 自动认领超过指定空闲时间的消息
- 比XCLAIM更便捷,可一次操作多条消息
XAUTOCLAIM mystream mygroup myconsumer2 1000 0-0
1) "0-0"
2) 1) 1) "1746885666676-0"
2) 1) "name"
2) "Eve"
3) "age"
4) "25"
5) "city"
6) "London"
3) 1) "1746886506263-0"
2) 1) "name"
2) "Shinerio"
3) "age"
4) "30"
5) "city"
6) "ShangHai"
4) (empty array)
XINFO GROUPS mystream
5) 1) "name"
2) "mygroup"
3) "consumers"
4) (integer) 2
5) "pending"
6) (integer) 2
7) "last-delivered-id"
8) "1746886620493-0"
9) "entries-read"
6) (integer) 3
7) "lag"
8) (integer) 0
xack mystream mygroup 1746885666676-0 1746886506263-0
(integer) 2
XINFO GROUPS mystream
9) 1) "name"
2) "mygroup"
3) "consumers"
4) (integer) 2
5) "pending"
6) (integer) 0
7) "last-delivered-id"
8) "1746886620493-0"
9) "entries-read"
10) (integer) 3
11) "lag"
12) (integer) 0
在实际应用中,通常需要
- 定期执行检查脚本,识别长时间未活动的消费者
- 检测空闲时间超过预设阈值(如60秒)的消息
- 将这些消息通过XCLAIM或XAUTOCLAIM重新分配给活跃的消费者
这一机制需要应用程序层面实现,Redis自身不会自动检测故障或重新分配消息。系统需要设计专门的监控和恢复组件来处理这些情况,确保消息不会因消费者故障而丢失。
评论