路由反射器通过“逻辑中转”解决了IBGP FullMesh的扩展性难题。它通过Originator_ID和Cluster_List确保了在打破物理环路限制的同时,逻辑上依然安全。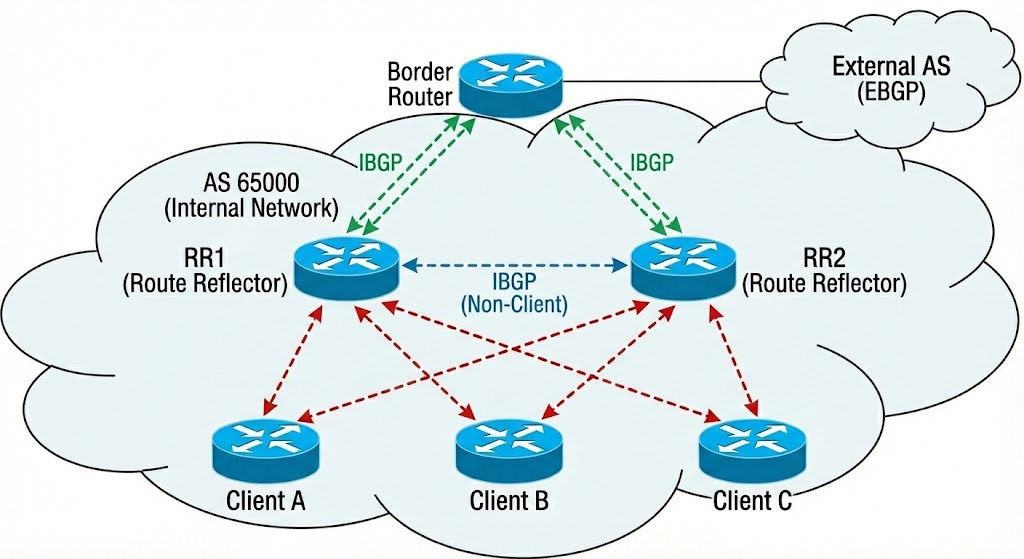
1. 为什么需要路由反射器?
在典型的IBGP(Internal BGP)网络中,为了防止环路,BGP 遵循一个核心法则:从 IBGP 邻居学到的路由,不会再转发给其他的 IBGP 邻居。
为了实现全网路由互通,传统做法是要求所有IBGP路由器之间建立全连接(Full-mesh)。
- 痛点: 随着路由器数量n的增加,连接数将以\frac{n(n-1)}{2}的速度剧增。这会消耗大量的 CPU 和带宽资源。
- 解决方案: 路由反射器(RR)打破了“非全连接不转发”的限制,允许指定设备将路由“反射”给其他邻居,从而将复杂的网状结构简化为星型结构。
2. 路由反射器的工作原理
在RR架构中,路由器被分为三种角色:
- RR (Route Reflector): 核心设备,负责反射路由。
- Client (客户端): 与RR建立反射关系的IBGP邻居。
- Non-Client (非客户端): 与RR建立普通IBGP关系的邻居。
2.1. 什么时候配置为 Client?
当你希望这台路由器完全摆脱 Full-mesh(全连接)的束缚,只与RR(路由反射器)建立邻居关系时,将其配置为Client。
典型场景:
- 接入层/汇聚层路由器: 这些设备通常性能有限,或者数量庞大。你只希望它们把路由丢给核心(RR),由核心负责分发。
- 辐射型(Hub-and-Spoke)拓扑: 所有的 Spoke 节点都应该被定义为 Client。
配置逻辑:
在RR上,你会看到类似peer 10.1.1.2 reflect-client的命令。
行为: RR 会把从一个 Client 收到的路由,转发给所有的其他邻居(包括其他 Client 和所有 Non-Client)。
2.2. 什么时候配置为Non-Client?
当你希望这台路由器依然遵循传统的 IBGP 全连接规则,但又需要与RR交换路由时,它就是 Non-Client。
典型场景:
- 核心骨干网路由器: 在一个AS内部,如果你有几台核心路由器性能都很强,它们之间已经建立了Full-mesh。其中一台被选作 RR,那么其他核心路由器对它来说就是Non-Client。
- 两个RR之间: 在双RR冗余组网中,RR1和RR2互为Non-Client。它们之间必须建立标准的 IBGP 邻居关系,以同步全网路由。
配置逻辑:
在RR上,你只需要正常配置peer 10.1.1.3 as-number 65001,不要加reflect-client关键字。
路由行为:
RR收到 Non-Client 的路由后,只会反射给 Client,不会反射给其他的 Non-Client(为了防止环路,除非通过 Client 中转)。
2.3. 常见情况
| 目标对象 | 建议角色 | 原因 |
|---|---|---|
| 普通分支路由器 | Client | 减少分支机构的 BGP 维护开销,实现简单拓扑。 |
| 冗余备份的 RR | Non-Client | RR 之间需要全路由同步,但不能互相作为客户端以防环路。 |
| 已存在全连接的核心机 | Non-Client | 保持原有的 Full-mesh 稳定性,仅利用 RR 覆盖其他分支。 |
| 性能较弱的旧设备 | Client | 将算力压力转移给 RR 节点。 |
2.4. 路由反射规则
RR在接收到路由后,会根据来源遵循以下反射逻辑:
- 来自Client: 反射给所有其他Client和所有Non-Client。
- 来自Non-Client: 反射给所有 Client(但不反射给其他 Non-Client)。
- 来自EBGP邻居: 反射给所有Client和 Non-Client。(IBGP标准行为)
2.5. 防环机制
由于打破了IBGP的防环规则,RR引入了两个特殊的路径属性来防止环路:
- Originator_ID: 记录路由起源者的Router ID。如果收到路由的Originator_ID是自己,则丢弃。
- Cluster_List: 记录路由经过的RR集群列表。如果RR发现自己的 Cluster_ID 已在列表中,则丢弃。
2.5.1. Originator_ID
Originator_ID 记录的是该路由在本地AS内部的“始发者”(即第一个发送该路由的IBGP路由器)的 Router ID。Originator_ID 的生成遵循以下严格逻辑:
- 谁来打?:由第一个接收到该路由并将其进行反射的 RR(路由反射器) 生成并添加。
- 打什么值?:RR 会提取该路由原始发送者(即它的 Client 或 Non-Client 邻居)的 Router ID,作为 Originator_ID 属性注入到 BGP 路由中。
- 后续变化吗?:一旦生成,该属性在路由经过后续的其他 RR(多级反射场景)时,保持不变。它像一张“出生证明”,标记了这路路由是从 AS 内部哪台机器最先发出来的。
场景演示:路由的“旅行日志”
假设 AS 65001 内有三台路由器:Router-A (Client), RR-1 (反射器), Router-B (另一个 Client)。
- 始发: Router-A(Router ID: 1.1.1.1)向 RR-1 发送一条 BGP 路由。此时,路由中没有 Originator_ID 属性。
- 反射: RR-1 收到后,准备反射给 Router-B。
- RR-1 发现这条路由是从 IBGP 邻居收到的且需要反射。
- RR-1 创建
Originator_ID属性,并将值设为 1.1.1.1(即 Router-A 的 ID)。 - RR-1 同时加上自己的
Cluster_List。
- 接收: Router-B 收到路由,看到
Originator_ID是 1.1.1.1,知道了这是 A 发出来的。
3. 使用场景:华为企业网与华为云 VPC
3.1. 大型企业骨干网
当企业内部有数十甚至上百台路由器时,RR 是必选项。通常会部署 双 RR 实现冗余备份,确保单点故障时路由依然可达。
3.2. 华为云跨 VPC 互通
在华为云(Huawei Cloud)环境下的混合云场景中,如果使用 企业路由器(ER) 连接多个 VPC 和线下 IDC,其底层逻辑往往也涉及 BGP 的路由分发。在某些复杂组网(如 SD-WAN 组网)中,RR 会部署在 Hub 节点,自动同步分支机构(Spoke)的路由。
3.3. 华为 VRP 平台配置示例
以下是在华为路由器上将一台设备配置为 RR,并指定邻居为客户端的典型命令:
# 进入 BGP 视图
[Huawei] bgp 65001
# 定义邻居并指定其所属的集群 ID(可选,默认为 Router ID)
[Huawei-bgp] cluster-id 1.1.1.1
# 将邻居 10.1.1.2 指定为路由反射器的客户端
[Huawei-bgp] peer 10.1.1.2 reflect-client
注意: 只需要在 RR 上进行配置,Client 端只需要将其视作普通的 IBGP 邻居进行配置即可,无需特殊指令。
4. RR与FullMesh
在BGP的实际运维中,RR星型网络和FullMesh结构这种“过渡期”或“配置重叠”的情况确实会发生。路由器会收到两份(或更多)针对同一前缀的路由更新,但最终在路由表(Routing Table)中只会保留一份“最优”路由。
4.1. 为什么会收到“重复”路由?
当网络中同时存在 RR(路由反射器)和 Full-mesh(全连接)时,一个客户端(Client)会通过两个路径获取路由:
- 路径 A: 通过与始发路由器的 IBGP 直接邻居 关系直接获取。
- 路径 B: 通过 RR 反射 过来获取(RR 从始发路由器接收后再转发给该 Client)。
4.2. BGP内存占用
在 BGP 的 Loc-RIB(本地路由信息库) 中,这两条路径都会被记录。这意味着路由器的内存(Control Plane)会承载双倍的 BGP 条目。如果网络规模极大(如承载了全网百万级路由),这种冗余会导致内存压力激增。
4.3. 路由器如何处理这两份路由?(选路决策)
虽然收到了多份更新,但 BGP 是一种极其“挑剔”的协议。华为 VRP 系统会按照 BGP 选路规则(Selection Process) 进行筛选,最终只有一条路由会变为 active 并下刷到 IP 路由表。
在 RR 和 Full-mesh 并存时,通常的选路逻辑如下:
- AS-Path/Local-Pref: 通常这两项在内部是相同的。
- IGP Cost: 比较到达下一跳(Next-hop)的距离。
- 关键点: 如果前面的属性全部相同,BGP 会进入后续比较。
- 非反射路由 vs 反射路由: 默认情况下,BGP 并不单纯因为路由是“反射”的就降低其优先级。
- Cluster_List 长度: 经过 RR 反射的路由会携带
Cluster_List。在某些实现中,不带 Cluster_List 的路由(即直接从 Full-mesh 邻居收到的路由)会被优先选择,因为它的路径更“短”(在逻辑跳数上)。
4.4. “并存”状态的危害
虽然BGP选路机制能保证转发不掉线,但这种架构被视为不良设计(Suboptimal Design),原因有三:
- 资源浪费: 维护多余的 TCP 会话消耗 CPU,存储多余的路由条目消耗内存。
- 路由震荡风险: 当物理链路波动时,由于存在多条逻辑路径,BGP 选路可能在 Full-mesh 路径和 RR 路径之间反复切换,导致网络收敛变慢。
- 管理混乱: 故障排查时,
display bgp routing-table看到的输出会非常冗长,很难一眼看清真实的流量走向。
4.5. 操作建议
如果你正在从 Full-mesh 向 RR 架构迁移,建议采取分步裁撤的策略:
- 建立 RR 关系: 先建立 RR 及其 Clients 之间的 BGP 邻居。
- 验证同步: 确认 Client 已经通过 RR 收到了所有必要的路由(此时路由表中会有重复条目)。
- 裁撤旧连接: 逐一删除 Client 之间原有的
peer命令。Warning在华为路由器上执行
undo peer [IP]会导致该 BGP 会话被立即彻底断开,原有的 Full-mesh 路由会瞬间失效。因此,请务必确保在删除旧邻居之前,Client 通过 RR 学习到的路由已经成功选路并进入 IP 路由表,以实现流量的无缝平滑切换
5. 多RR冗余设计
在大型网络或华为云VPC核心组网中,单台RR(路由反射器)是典型的单点故障源(Single Point of Failure)。一旦 RR 宕机,整个 AS 内部的 BGP 路由传递将陷于瘫痪。为了实现容灾,通常采用多 RR 冗余设计(通常是双 RR)。以下是实现容灾的核心方案、防环机制及华为设备的配置实践。
5.1. 多 RR 冗余的基本架构
最常见的容灾模式是 “双中心(Dual-RR)” 架构。在这种模式下:
- 两个 RR 之间: 必须建立普通的 IBGP 邻居关系(即互为 Non-Client)。
- Client 路由器: 同时与两台 RR 建立 IBGP 邻居,并分别接收来自两个 RR 的路由更新。
5.1.1. 控制面冗余
IBGP 路由器(Client)会从两个RR收到两条完全相同的路由,实现“无缝容灾”。在双 RR 架构中,当一台始发路由器(Originator)发布一条路由时:
- 它会同时发送给 RR-1 和 RR-2,当 RR-1 失效时,Client 依然可以通过 RR-2 学习到全网路由。
- RR-1 将路由反射给所有的 Client。
- RR-2 也会将路由反射给所有的 Client。
结论: 所有的Client路由器的 BGP 内存表(Loc-RIB)中,针对同一个目的地,都会存在两个条目:一个下一跳是指向 RR-1 的(逻辑上),另一个是指向 RR-2 的(逻辑上)。但请注意,由于 RR 默认不修改下一跳,这两条路由的真正Next-hop通常都是始发路由器的 Loopback 地址。
5.1.2. 数据面冗余(选路机制)
RR 只负责传路由。由于 Client 同时从两个 RR 收到同一条路由,它会根据 BGP 选路规则选出最优路径。BGP 协议不会允许两条重复路由同时指导转发。
- 选出最优(Best): 路由器会根据 BGP 选路规则(Local-Pref -> AS-Path -> Origin -> MED -> IGP Cost...)对这两条路由进行比对。
- 优选结果: 最终只有一条路由会被标记为
valid & best(在华为设备上显示为*>)。 - 下刷转发表: 只有这条最优路由会被下刷到 IP 路由表(Routing Table)和转发信息库(FIB)中。
结论: 路由在 BGP 协议层面是“重复”存在的(为了备份),但在 IP 路由表和实际转发层面是“唯一”的。
5.1.3. “重复”路由的正面价值:容灾
这种“重复”正是冗余设计的精髓所在:
- 热备份: 当 RR-1 发生故障(如进程崩溃或链路中断)时,Client 会立即感知到与 RR-1 的 BGP 会话失效。
- 秒级收敛: 此时,原本处于“备份”状态的来自 RR-2 的路由会自动被提升为
best,并立即更新 FIB。由于路由已经在内存中,不需要重新向 RR-2 请求,从而实现了极快的网络收敛。
5.1.4. 潜在风险:内存压力
如果你的网络中路由条目极其庞大(例如承载了完整的互联网路由表,约 90 万条):
- 内存翻倍: 每一个 Client 确实需要双倍的内存空间来存储这些 BGP 路径属性。
- 华为设备建议: 对于内存较小的接入层交换机或路由器,建议在 RR 上配置 路由聚合 或者 发送缺省路由(Default Route),以减轻 Client 的存储负担。
5.2. 关键防环机制:Cluster_ID
在多RR环境下,为了防止 RR 之间循环反射路由,必须引入 Cluster_ID(集群 ID)。这里有两种主流的设计思路:
5.2.1. 方案 A:相同 Cluster_ID(最常用)
- 配置: 将两台RR配置相同的
cluster-id(例如1.1.1.1)。 - 原理: RR-1 反射给 RR-2 的路由会携带 Cluster_ID。RR-2 收到后发现该 ID 与自己相同,会直接丢弃。
- 优点: 极大地降低了 RR 之间产生环路的风险。
- 缺点: 在某些极端物理链路断开的情况下,可能会导致路由无法到达备份 RR,但通常在全连接骨干网中这不是问题。Tip
“架构要求: 采用此方案时,必须确保所有 Client 都是双归属连接到两台 RR。因为 RR 之间不会同步 Client 的路由,如果存在单归属的 Client,将导致部分网络节点出现路由黑洞。”
5.2.2. 方案 B:不同 Cluster_ID
- 配置: RR-1 和 RR-2 使用各自不同的
cluster-id(通常默认使用 Router ID)。 - 原理: 依靠
Cluster_List记录路径。路由会经过 RR-1 反射给 RR-2,RR-2 再次反射给它的 Clients。 - 优点: 路由可靠性更高。
- 缺点: 增加了BGP路由表的复杂度和内存占用。
5.3. 冗余环境下的选路一致性
在容灾场景下,如果RR-1和RR-2传递给 Client 的路由属性不一致,会导致次优路径或环路。
最佳实践指南:
- Next-hop-local: 在RR上反射路由时,默认不修改下一跳。务必确保所有Client都能通过 IGP(如 OSPF)学习到路由始发者的下一跳地址。
- 属性对称: 确保两台 RR 上的 Export 策略、Local Preference 等配置完全一致。
5.4. 进阶:多级 RR 容灾 (Hierarchical RR)
在超大规模网络中,会存在“省-市-县”三级架构。此时,上一级的 Client 同时又是下一级的 RR。
- 容灾要点: 每一级都必须部署双机,且每一级通过
Cluster_List来确保纵向防环。
5.5. 总结
多 RR 容灾的核心在于 “物理双连接 + 逻辑 Cluster_ID 防环”。
- 如果追求极高安全性:建议使用相同 Cluster_ID,配置简单且防环能力最强。
- 如果追求最高可用性:建议使用不同 Cluster_ID,配合合理的策略干预。
评论