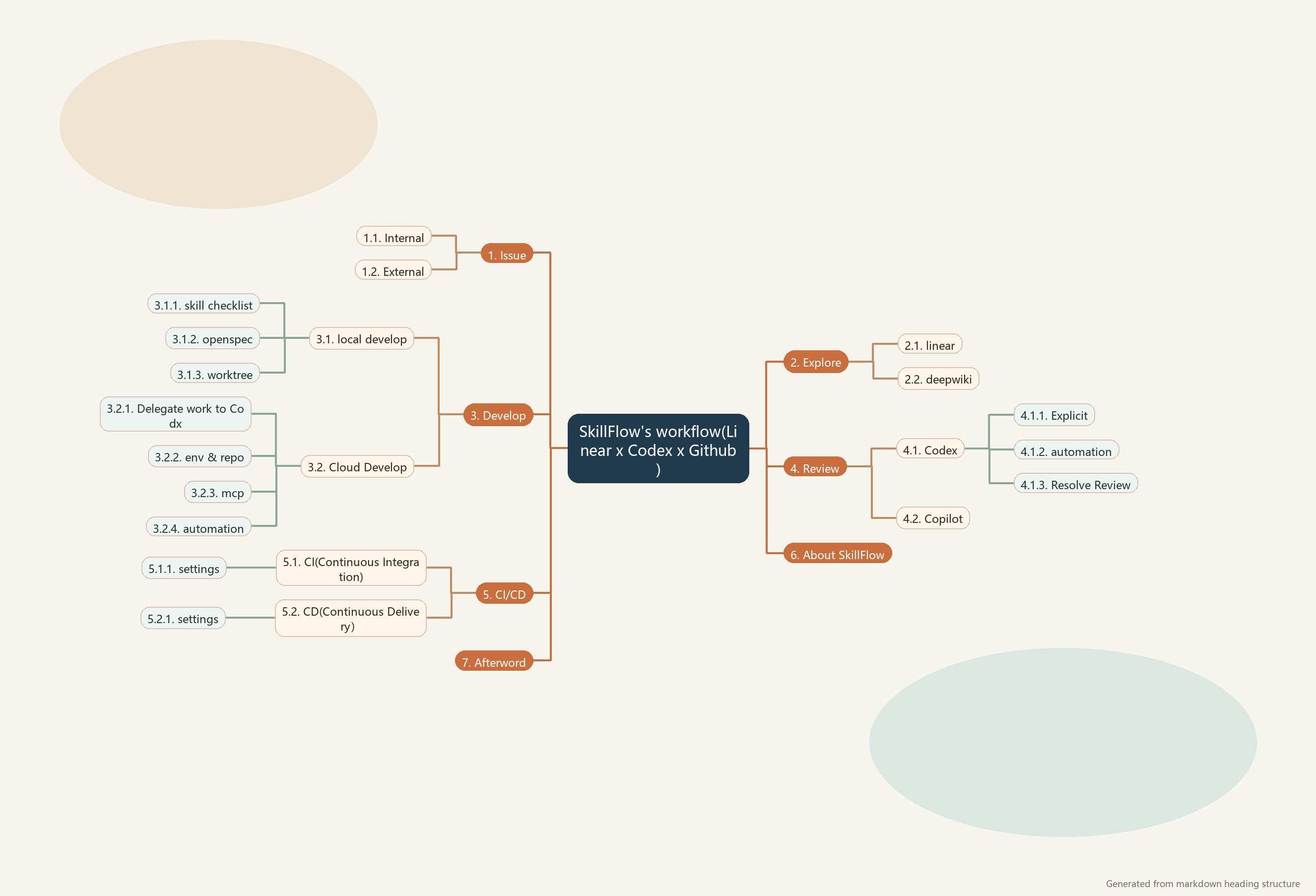
本文以SkillFlow项目为例,系统整理我在AI 辅助研发中的一套工作方法:如何从发现需求、问题探索、代码实现、审查协作,一路走到CI/CD交付。我关心的不是“某个 AI 工具有多强”,而是一个更基础的问题:如何把零散的AI能力,组织成一条稳定、可复用、可迭代的研发流水线。
在我的实践里,这条流水线大致分为五个阶段:
- Issue:把需求、缺陷、反馈统一收敛为可管理的问题对象
- Explore:围绕issue做澄清、追问、验证与方案探索
- Develop:在本地或云端执行实现,并保持上下文隔离
- Review:让AI和人类共同参与代码审查,尽早发现风险
- CI/CD:通过自动化测试与发布流程,把“代码完成”转化为“可交付结果”
如果只用一句话概括这套方法,那就是:
先把问题定义清楚,再把上下文隔离开来,最后用测试和自动化把结果钉死。
1. Issue
项目管理的本质,是issue管理,任何项目都不是从代码开始,而是从问题开始。在Linear|linear里,我把一切工作对象——无论是 bug、feature、refactor还是用户feedback——都统一视作issue。这样做的好处是:需求、讨论、优先级、负责人和状态都能落到同一个载体上,项目管理也就变成了issue管理。
我通常把 issue 分成两类:
- Internal:团队主动规划的任务,例如架构演进、功能设计、版本路线图
- External:来自用户或外部环境的输入,例如GitHub issue、反馈和缺陷报告
这样划分的目的不是为了分类而分类,而是为了区分两种不同的驱动力: 前者来自内部规划,后者来自外部压力。
1.1. Internal
根据功能特性、架构模块或版本规划等issues划分多个project。
- 在规划大粒度特性(project)时,撰写详细项目description,选中后一键转换为issue
- 手工在指定project下创建issues
1.2. External
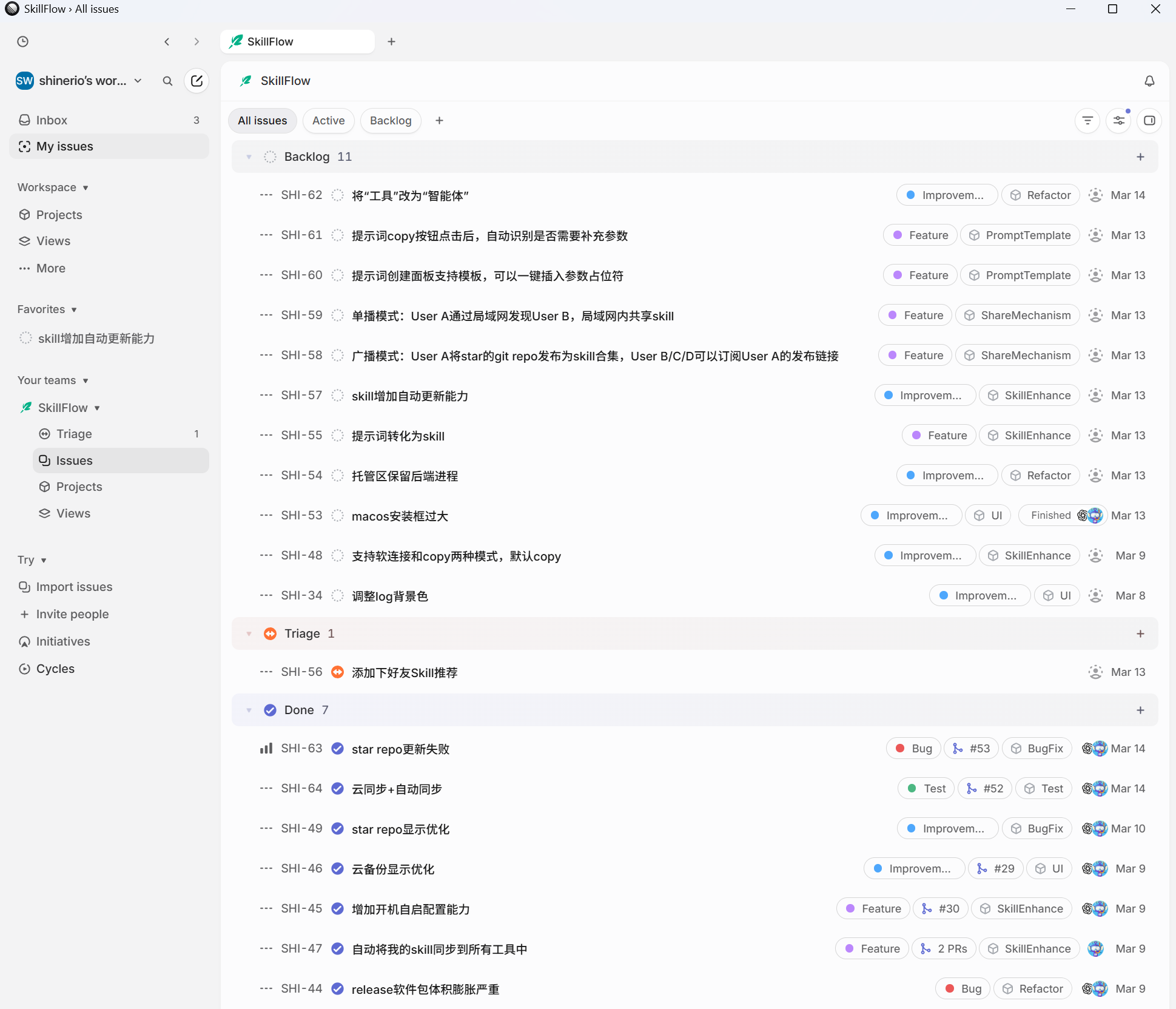
- 项目在github开源,用户在github上提交的issues会自动同步到linear中(状态为triage)
- 我会定期进行人工分类,审视issue的合理性,为合理的issue设置project/label/priority/assignee等,放到backlog中(business计划支持配置规则自动分类)
2. Explore
探索不是“问AI”,而是把模糊问题压缩成可执行问题。我把探索阶段理解为一个“降熵”过程。最开始的问题通常是模糊的、跳跃的,甚至彼此矛盾;而探索的目标,是把这些不确定性压缩成后续可以实现的决策。
我常用两种方式:
- 在Linear中围绕issue持续追问
- 借助deepwiki这类工具理解代码库
2.1. linear
我会把灵感、疑问、边界条件都沉淀到issue评论区,通过@Codex发起多轮讨论。这样做的价值不只是“得到回答”,而是把思考过程本身保存成项目资产,方便日后回看。
优缺点:
- 对话效率低,回答链路相对更长,因为需要在云端环境中拉起分析上下文,但优势是结论更贴近当前代码状态
- 内容时效性好,能够基于最新代码进行问答
2.2. deepwiki
它更适合做“结构性认知”——例如帮助新加入的开发者快速理解模块关系、核心概念和代码入口。但这类索引工具通常不是实时的,因此更适合做入门和全局理解,不适合回答对代码新鲜度要求很高的问题。
优缺点:
- 上手门槛低,web页面交互方便
- 对话效率高,代码与文档已经提前索引好,AI回答问题效率较高
- 内容时效性低,无法实时刷新索引,通常更新间隔需要7天以上
3. Develop
开发的核心不是“让 AI 写代码”,而是“让上下文有序流动”。很多人理解AI开发,关注点是“模型能力有多强,会不会写代码”。 但这通常属于外部不可控因素,在我看来,作为开发者,真正影响交付质量的不是模型能力,而是上下文管理能力。
3.1. local develop
我在本地开发,主要使用superpowers这套工作集,把任务拆成几个明确阶段。
需求澄清 → 方案设计 → 计划制定 → 隔离执行 → 测试约束 → 代码审查 → 分支收尾
它背后的原则其实很简单:
- 不清楚的需求,先澄清,不急着写代码
- 可拆的任务,先写计划,避免边做边想
- 彼此独立的任务,隔离上下文,避免互相污染
- 任何修复或功能实现,都尽量先写失败测试,再写最小实现
- 在宣称“完成”之前,先拿出验证证据,而不是主观判断
工作流不是为了增加步骤,而是为了减少返工。
3.1.1. superpower skill checklist
| Skill | 目的(概括) | 激活阶段(生命周期) | 典型输入 | 典型输出 | 主要配置/约定(若有) |
|---|---|---|---|---|---|
| using-superpowers | 引导:解释技能系统、要求每次任务前检查/调用技能 | SessionStart 注入后持续生效 | 会话启动上下文;平台 Skill 工具 | 触发其它技能的调用决策 | 由 hooks/session-start 自动注入全文 |
| brainstorming | 通过提问把模糊想法收敛成可审阅的 spec/design | 写代码前;需求/设计不清晰时 | 用户目标、现状、约束 | spec 文档(默认 docs/superpowers/specs/...)及设计权衡 |
默认 spec 路径约定;需分段呈现核准 |
| using-git-worktrees | 创建隔离 worktree/分支并验证干净基线 | 设计通过后;执行计划前 | git 仓库、目标分支名、项目依赖 | 新 worktree 目录、分支、依赖安装、基线测试结果 | 目录选择优先级:现有 .worktrees/worktrees→CLAUDE.md→询问;需 git check-ignore 验证忽略 |
| writing-plans | 基于 spec 生成可执行、细粒度、含验证步骤的 plan | spec/设计批准后;触碰代码前 | spec 文档、代码库结构 | plan 文档(默认 docs/superpowers/plans/...),含任务/步骤/命令 |
plan 头部要求后续用 SDD 或 executing-plans 执行;支持用户覆盖 plan 存放位置 |
| subagent-driven-development | 在同会话中按 plan 调度“每任务一个子智能体+两阶段评审” | 有 subagents 且 plan 可拆成相对独立任务时 | plan 文本、任务上下文、spec | 多次小步提交、评审结论、最终汇总;然后进入收尾技能 | 强依赖:worktrees、writing-plans、requesting-code-review、finishing-a-development-branch;子智能体执行中应使用 TDD |
| executing-plans | 无/少 subagents 时:按 plan 分批执行并设检查点 | 有 plan 但不使用/不具备 subagents;或另开会话执行 | plan 文件 | 执行后的代码/测试结果;完成后调用 finishing-a-development-branch | 明确要求完成后必须调用 finishing-a-development-branch;并提醒“有 subagents 时优先用 SDD” |
| test-driven-development | 强制 RED–GREEN–REFACTOR;先测后码 | 实现阶段(每个行为/修复) | 需求/任务描述、测试框架 | 先失败测试→最小实现→绿色→重构;小步提交 | 规则:未见失败不算测试;禁止先写生产代码 |
| requesting-code-review | 在任务间/批次后发起评审,阻止问题级联 | SDD 每任务后;executing-plans 每批后;合并前 | git SHAs、plan/需求、变更摘要 | review 结论(按严重度),后续修复动作 | 通过 Task 工具调度 code-reviewer 子智能体;模板 code-reviewer.md |
| receiving-code-review | 收到反馈时不做“社交表演”,而是按“读完→复述/澄清→验证→评估→回应→逐条实施并测试”的技术流程处理 | 收到反馈后、实施建议前 | review 评论、代码现状 | 澄清问题、逐条实施/反驳并验证 | 约束“在任何不清晰项未澄清前不要动手” |
| systematic-debugging | 阶段根因分析,禁止“拍脑袋修复” | 任何 bug/失败/异常出现时 | 错误信息、复现步骤、日志、差异 | 根因定位、最小假设验证、再进入实现(可用 TDD) | 铁律:未完成 Phase 1 不得提出修复;Phase 4 建议用 TDD 写失败用例 |
| verification-before-completion | 在宣称“完成/修复/通过”前必须跑验证命令并读输出 | 任何“要宣布成功/提交/PR/进入下一任务”前 | 要证明的主张、对应验证命令 | 可审计的证据(命令+输出摘要) | 区分 Claude Code vs Cursor 注入字段体现“避免重复上下文”同一精神:证据先行 |
| dispatching-parallel-agents | 多个独立问题域并行调度子智能体 | 多处独立失败/子问题互不依赖时 | 多个失败域的上下文(各自独立) | 并行调查/修复结论,最终整合与全量验证 | 强调“不要共享会话历史”,每 agent 范围要窄;并行运行示例(Task 并发) |
| finishing-a-development-branch | 测试验证后给出 4 个收尾选项并执行(合并/PR/保留/丢弃) | 当任务完成、准备集成时 | 当前分支/worktree、测试命令、目标基线分支 | 合并/PR 或清理 worktree;或保留/丢弃 | 明确“先验证测试→再给选项”;且被 SDD 与 executing-plans 调用 |
| writing-skills | 创建/修改/验证技能:把“写技能”当作过程文档版 TDD | 维护技能库/自定义技能时 | 失败案例(没有技能时 agent 会犯错)、技能草案 | 新技能目录/SKILL.md 与配套文件;验证/迭代记录 |
指定技能存放:Claude Code ~/.claude/skills,Codex ~/.agents/skills/;frontmatter 仅支持 name/description |
3.1.2. example
3.1.2.1. 使用systematic-debugging定位git问题
核心逻辑:在完全理解故障根源之前,禁止任何修复尝试。
3.1.2.1.1. 工作原理:科学实验法
该Skill的底层逻辑借鉴科学实验方法论,本质上不是一个“修 bug 技巧”,而是一种证据驱动的问题求解流程。它把调试从“猜哪里坏了”改造成“验证哪条因果链出了问题”。
- 因果律优先:它假设任何 Bug都有一个明确的起点(Root Cause)。目前的错误表现只是“结果”,而“结果”是不值得修复的,必须修复“原因”。
- 隔离变量:在Phase 3中,它要求每次只改变一个变量。如果同时改动多处,你将无法确定是哪个改动起效了,或者是否一个改动掩盖了另一个问题。
- 证据驱动:它不相信“我觉得”、“应该是”,它只相信日志、堆栈跟踪(Stack Trace)和可复现的测试用例。
在我的个人实践里,这种方法通常比随机试错更快收敛。它最大的收益不是神奇地提升速度,而是减少无效修改和连带损伤。
3.1.2.2. 使用工作流对项目进行重构
brainstorming(需求澄清&方案设计) -> 基于TDD开发 -> 收尾阶段验证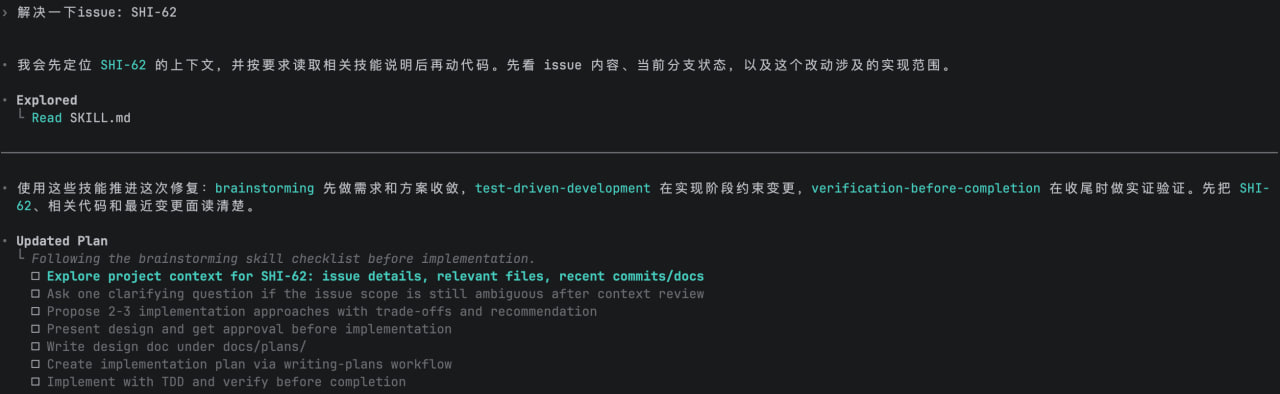
- 使用subagent-driven-development模式开发
- 创建新的worktree
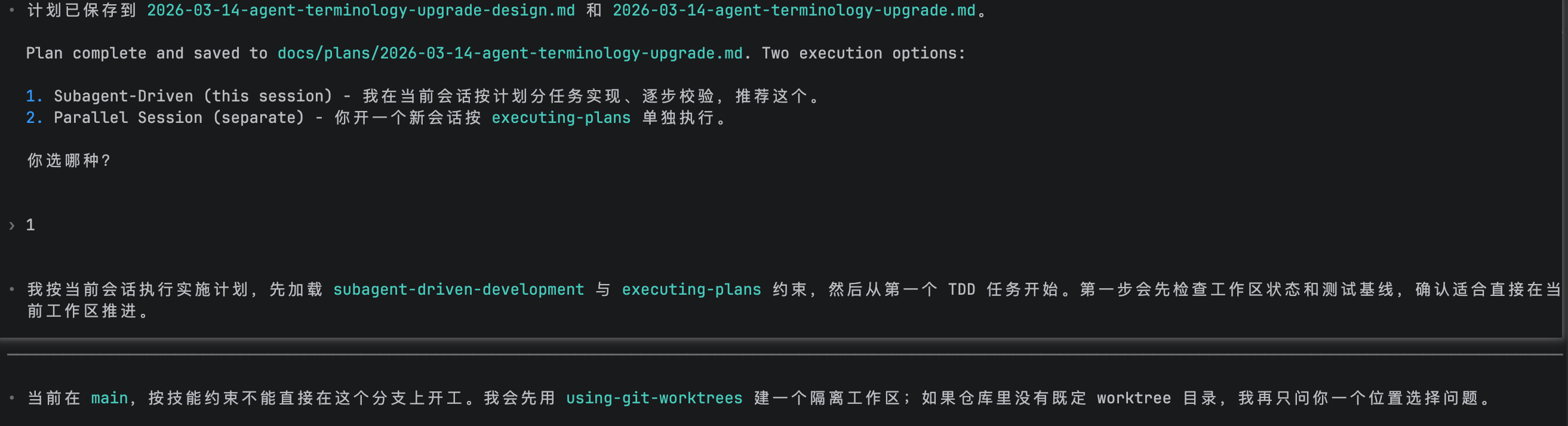
- 严格遵守TDD模式,每个task按照Red-Green-Refactor流程处理
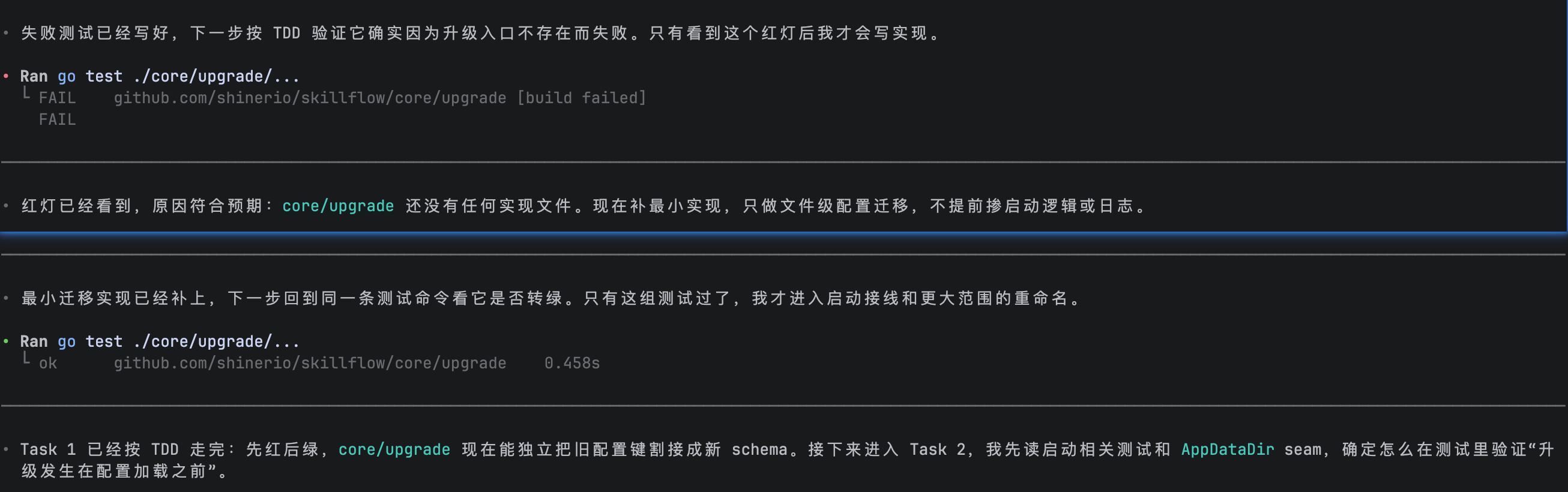
- commit前进行最后的测试验证

3.1.3. openspec
Explore -> Proposal -> Spec -> Design -> Task -> Implement -> Archive
superpowers: 非强制性工作流,更像是给AI的“瑞士军刀”工具箱,本质是skill的封装和复用,用户可以组合出来各种复杂的工作流。灵活度高、创造性强,适合单兵作战
openspec: 一套完整的开发流程规范,需求与设计文档的持续更新与迭代,团队共享一份,archieve很关键。约束更多,但团队协作时的一致性也更强。
3.1.4. worktree
worktree解决的不是“多开目录”,而是“并行任务的上下文隔离”。git worktree 的价值,不在于它能复制多个文件夹,而在于它允许你在共享同一份 Git历史的前提下,为不同任务建立独立工作区。这在AI协作开发里尤其重要,因为模型对上下文非常敏感。如果多个特性、多个 bug 修复、甚至人工 review都挤在同一个目录里,模型很容易被无关修改干扰。
典型场景包括:
- 并行开发多个独立特性
- 并行修复多个互不相关的 bug
- 让 AI 在一个
worktree中实现代码,同时在另一个worktree中由人进行review或验证
它不能消灭合并冲突,但能显著降低上下文串扰带来的混乱。虽然并发开发仍然会带来合并成本,但AI辅助可以显著降低冲突处理、回归验证与整理分支的负担。当配合TDD、自动测试和受控合并流程时,并行开发会变得更可控,而不是更冒险。
3.2. Cloud Develop
在通勤、散步,或暂时不便打开电脑的场景下,在一些轻量级开发场景里,云端开发已经让“不打开电脑也能推进任务”变成现实。
- Codex
- Claude CodeTip
目前一部分主流AI编程产品已经提供了云端任务执行或托管式开发能力,允许开发者不在本地打开完整IDE的情况下推进任务。
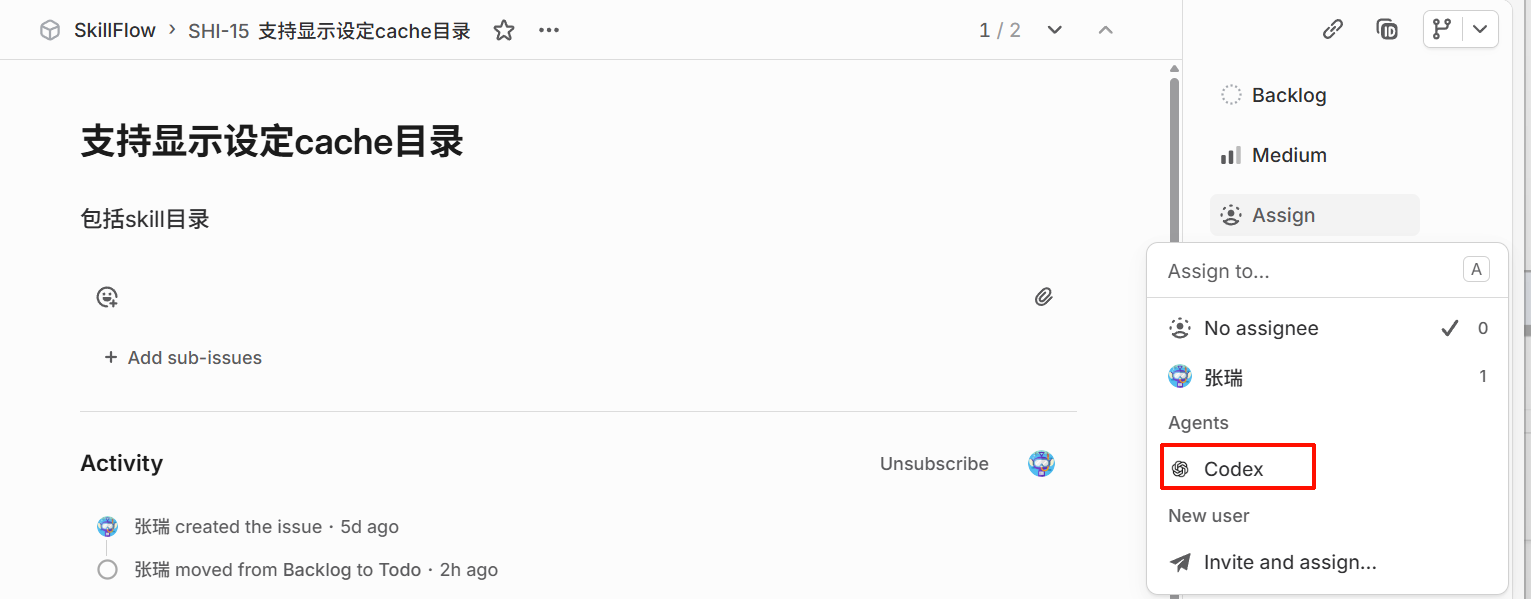
3.2.1. Delegate work to Codx
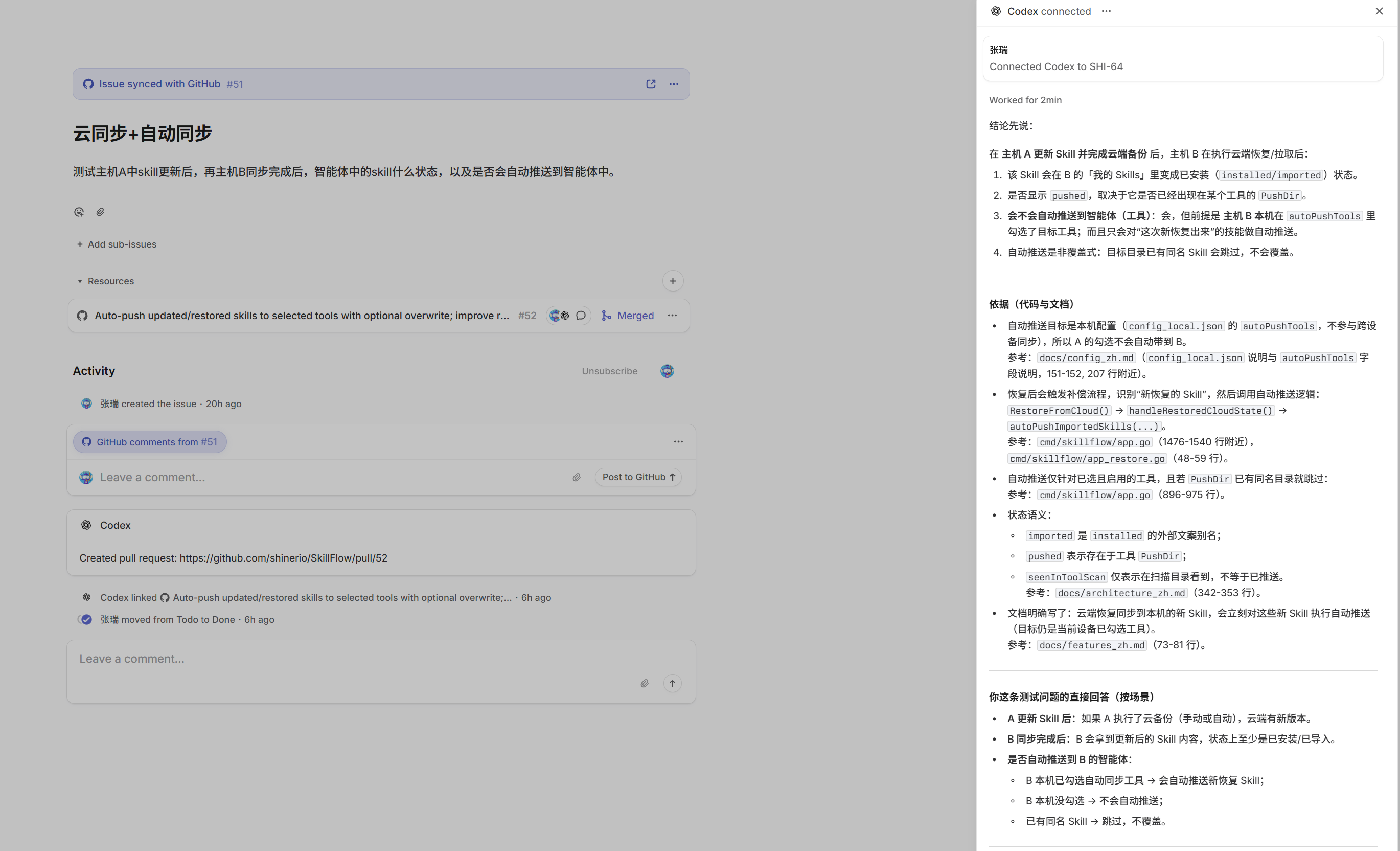
- 评论区
@Codex进行提问或任务分配 - 直接assign任务给Codex
Activity面板可以看到任务完成后的反馈,还可以打开task链接追踪更多细节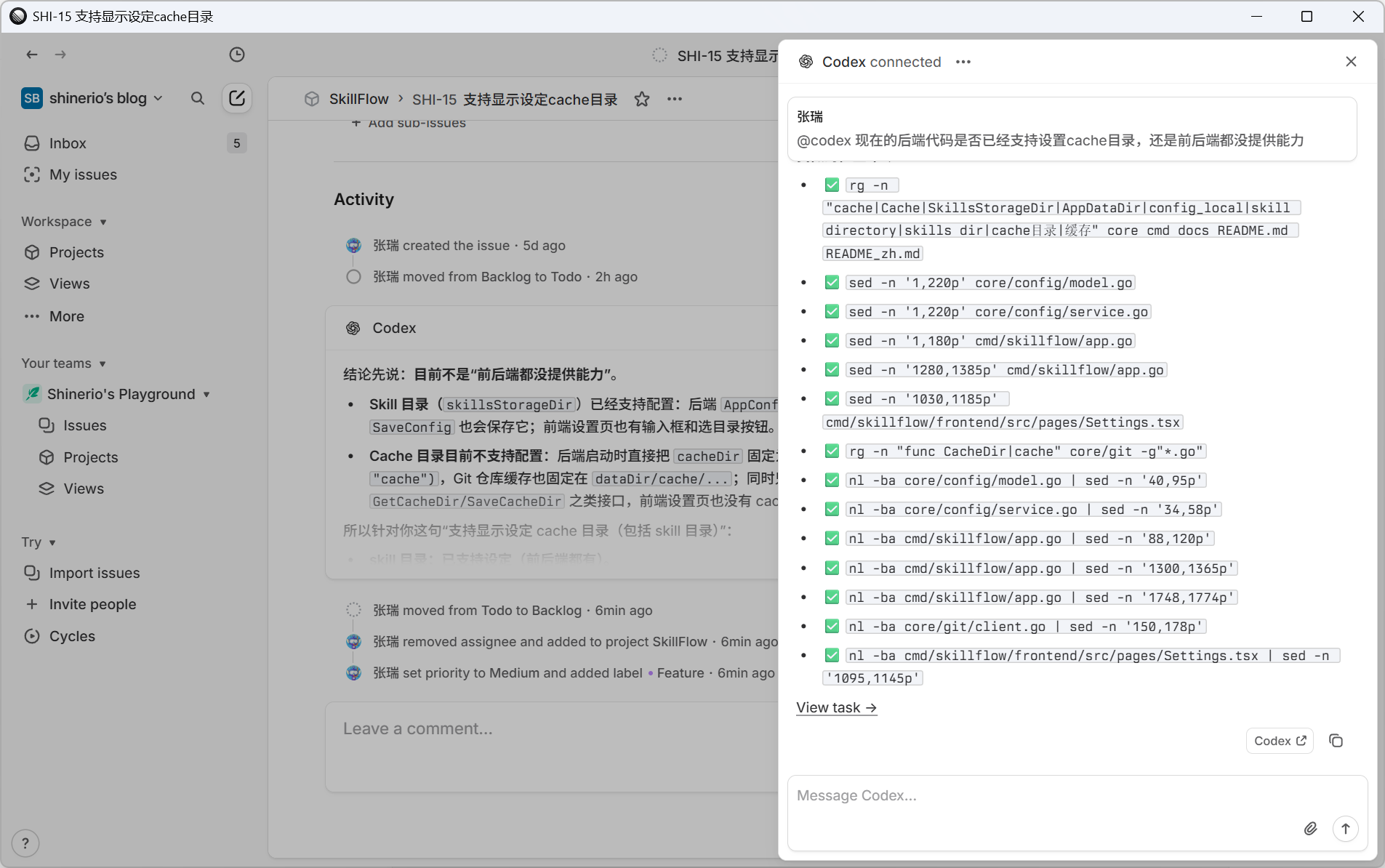
3.2.2. env & repo
- Environment:Linear会基于问题上下文推荐一个repo。Codex会自动选择一个最符合匹配Linear建议的Environment。如果请求存在歧义的,则使用最常使用的Environment兜底。或者,用户可以显式指定,例如使用
@Codex fix this in shinerio/SkillFlow - Repo:Task基于codex中environment关联的第一个repo的默认分支运行。(codex中支持给一个github repo创建多个environment)
- 如果没有合适的environment或者repo,Codex会在Linear中回复在重试之前如何解决issue的指令。
3.2.3. mcp
通过mcp工具,本地开发的时候,也可以直接将issue分配给AI完成。
配置命令codex mcp add linear --url https://mcp.linear.app/mcp
支持功能
🔌 MCP Tools
• linear
• Status: enabled
• Auth: OAuth
• URL: https://mcp.linear.app/mcp
• Tools: create_attachment, create_document, create_issue_label, delete_attachment, delete_comment, extract_images, get_attachment, get_document, get_issue,
get_issue_status, get_milestone, get_project, get_team, get_user, list_comments, list_cycles, list_documents, list_issue_labels, list_issue_statuses, list_issues,
list_milestones, list_project_labels, list_projects, list_teams, list_users, save_comment, save_issue, save_milestone, save_project, search_documentation,
update_document
• Resources: (none)
• Resource templates: (none)
使用示例: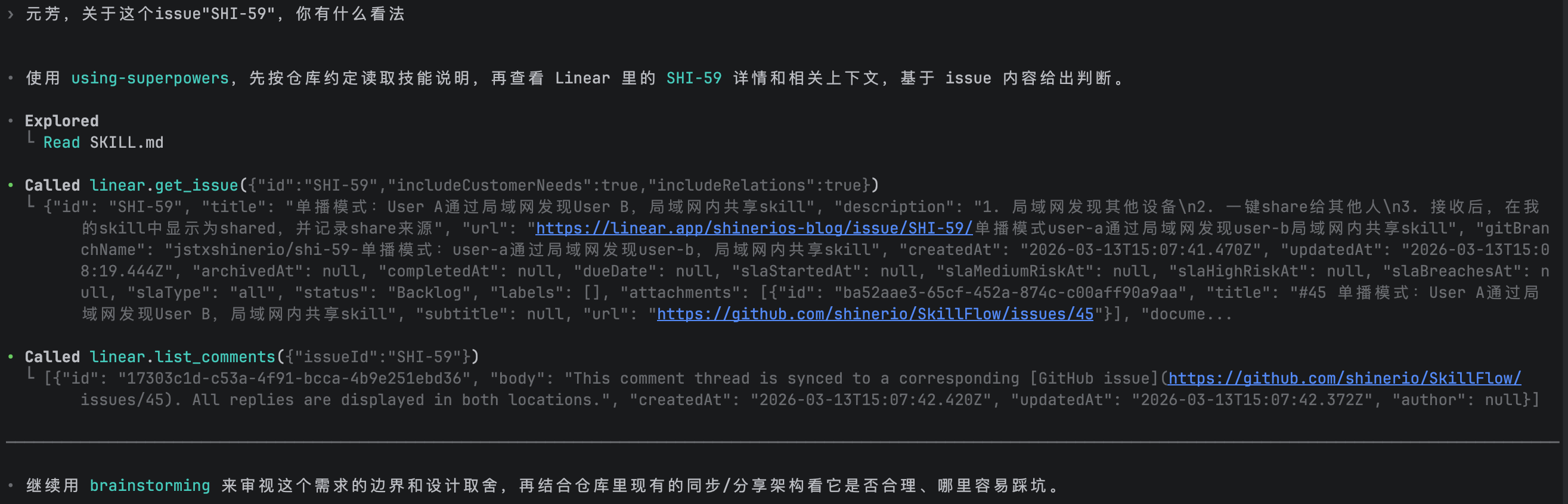
3.2.4. automation
Business and Enterprise plans可以通过triage rules实现issues自动流转
- 自动将任务分配给Codex
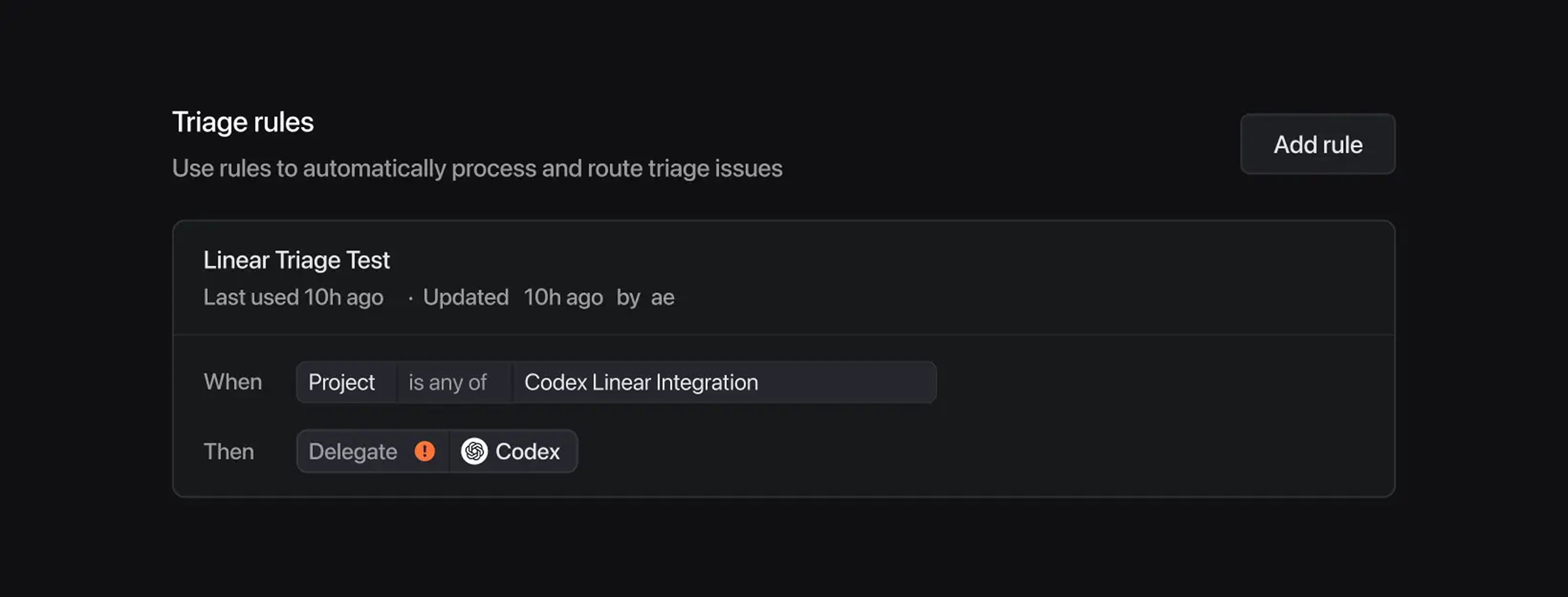
- 自动给指定客户打“高优先级”标签
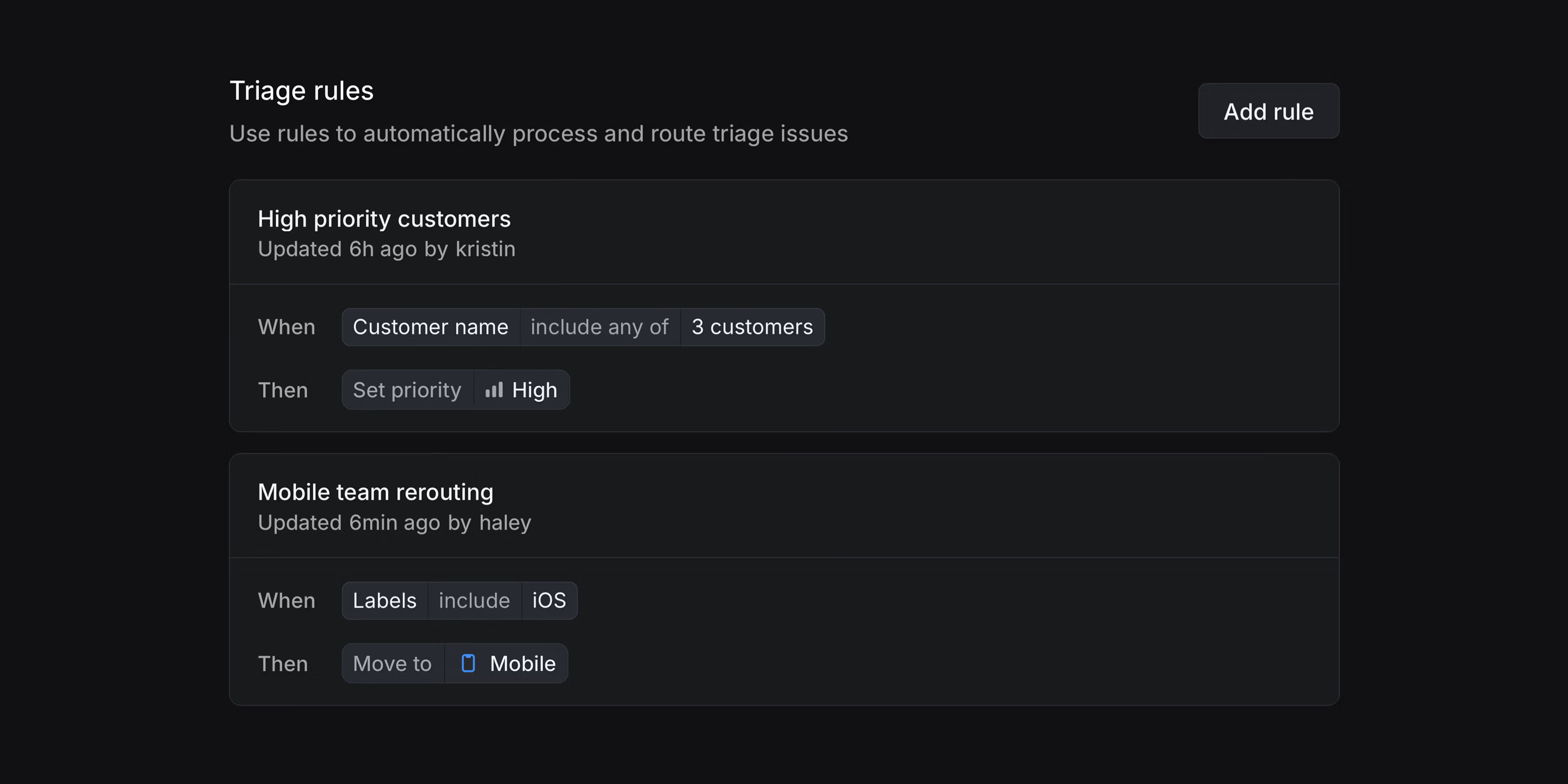
4. Review
4.1. Codex
4.1.1. Explicit
通过评论的方式,显示触发Codex review,例如@Codex review it。甚至可以在评论区让Codex重点关注某些方面的内容,如@Codex review代码,重点关注是否存在安全凭据保存不当的问题
4.1.2. automation
在Codex中可以开启自动review,一旦有PR创建,Codex便会自动开启review。
- on PR open
- on every push
4.1.3. Resolve Review
可以使用@codex的方式进行回复,要求codex进行修复,修复后会触发branch update。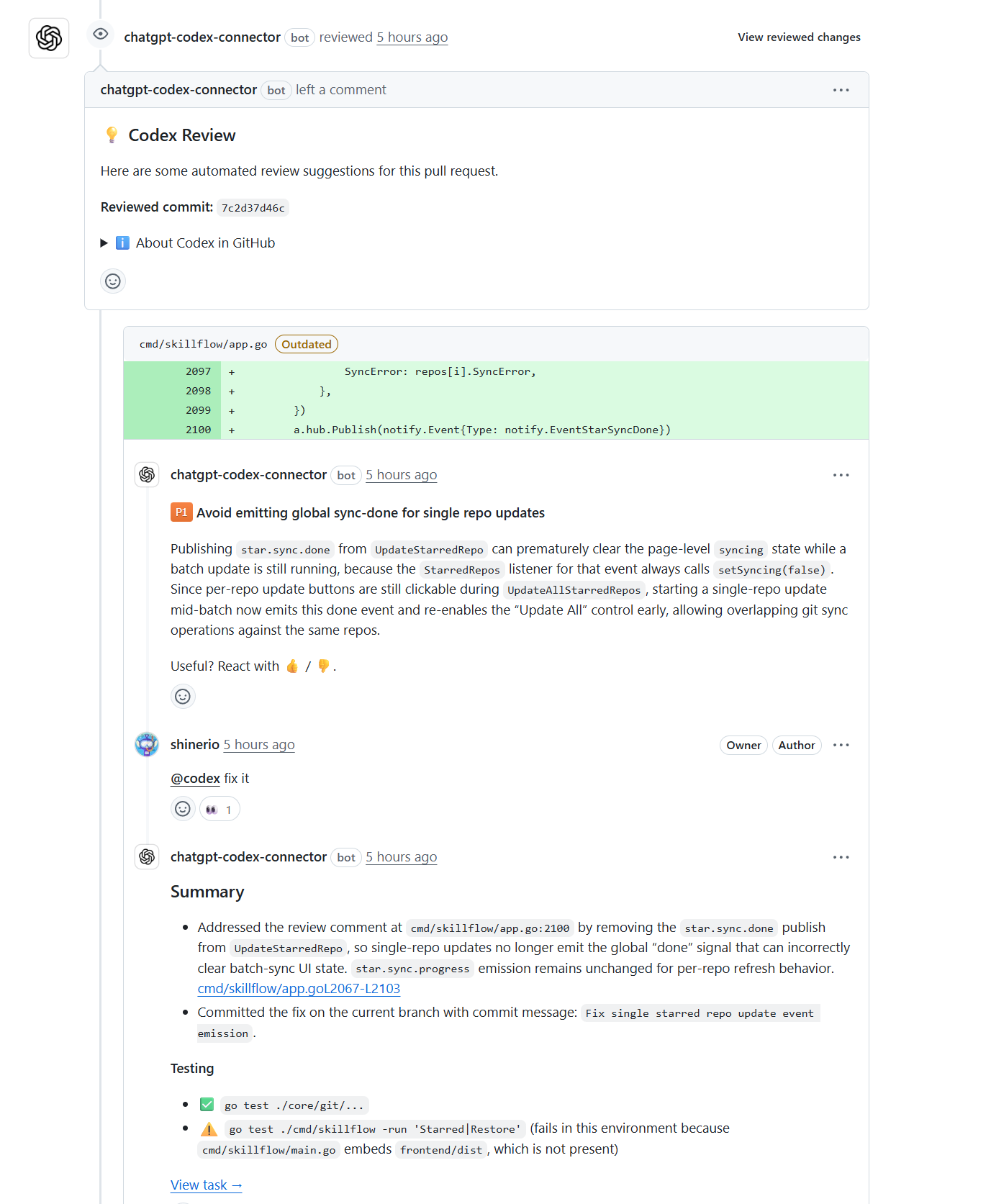
4.2. Copilot
GitHub Copilot也提供代码审查能力,但目前处于只有收费用户可用。
5. CI/CD
5.1. CI(Continuous Integration)
- 核心动作: 提交代码 -> 自动拉取 -> 自动编译 -> 自动运行单元测试。
- 目的: 尽早发现代码冲突和逻辑错误。如果测试没通过,构建就会“失败”,开发者必须立即修复。
5.1.1. settings
定义CI流水线
on:
pull_request:
branches:
- main
types:
- opened # 新建PR时跑
- synchronize # PR分支有新提交时跑
- reopened # 重新打开PR时跑
- ready_for_review # 从draft转正式时跑
设置CI门禁:settings -> rules -> rulesets
- Require a pull request before mergingRequire all commits be made to a non-target branch and submitted via a pull request before they can be merged.
- Block force pushes
- Require status checks to pass -> verify-main
不允许push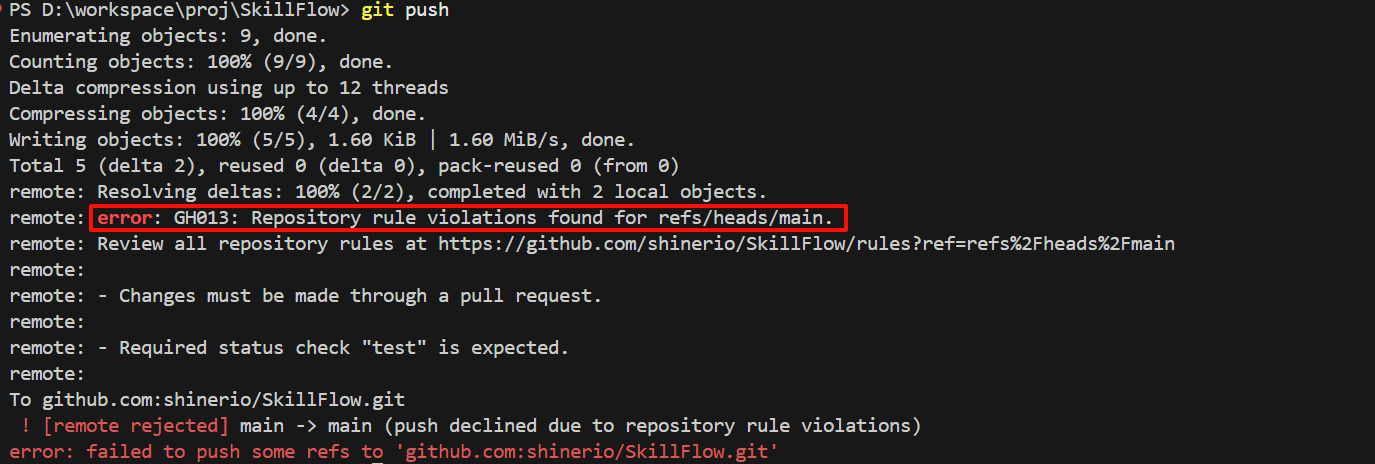
门禁未通过,不允许合入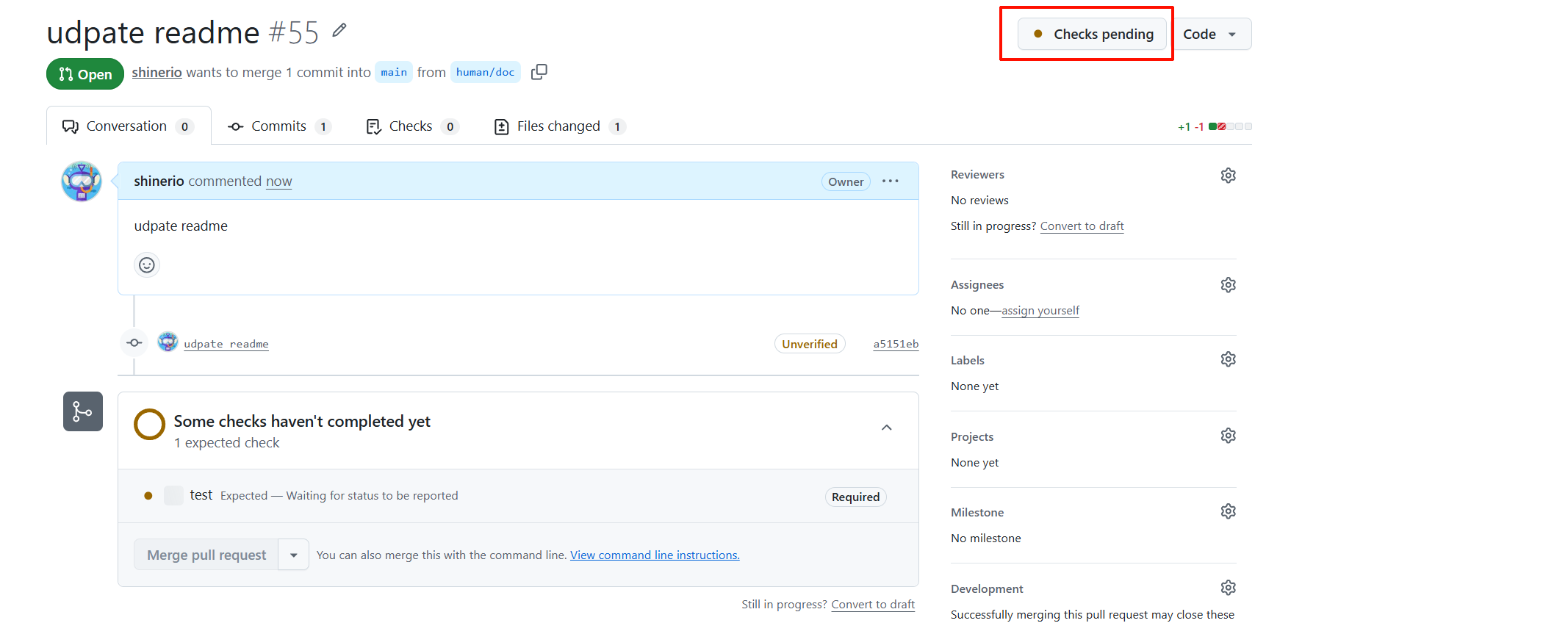
门禁通过后,方可合入
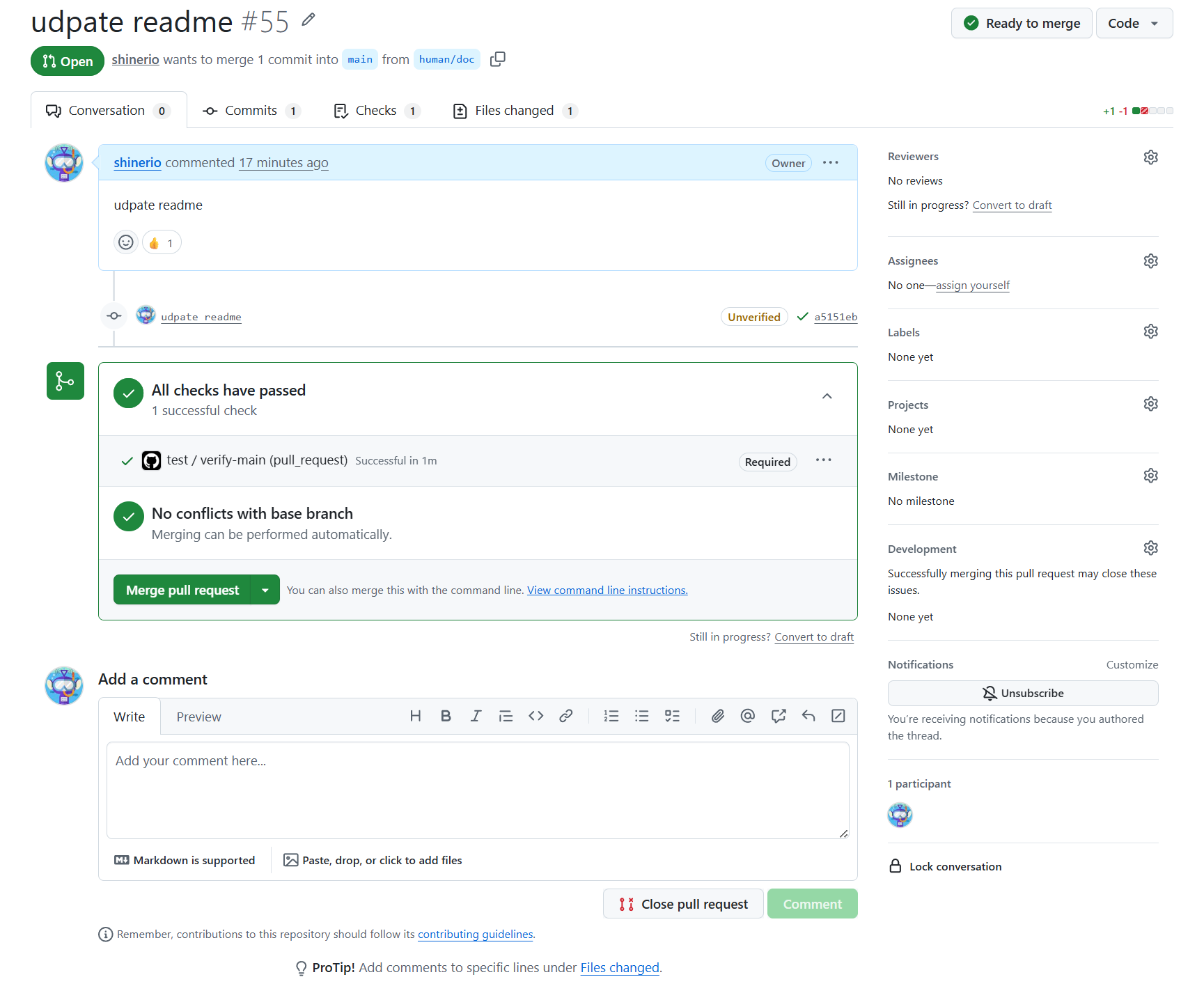
5.2. CD(Continuous Delivery)
5.2.1. settings
基于tag触发的自动构建与发布流程
on:
push:
tags: ['v*']
携带tag v*的commit被push后会自动触发release流水线,发布macos/windows版本客户端。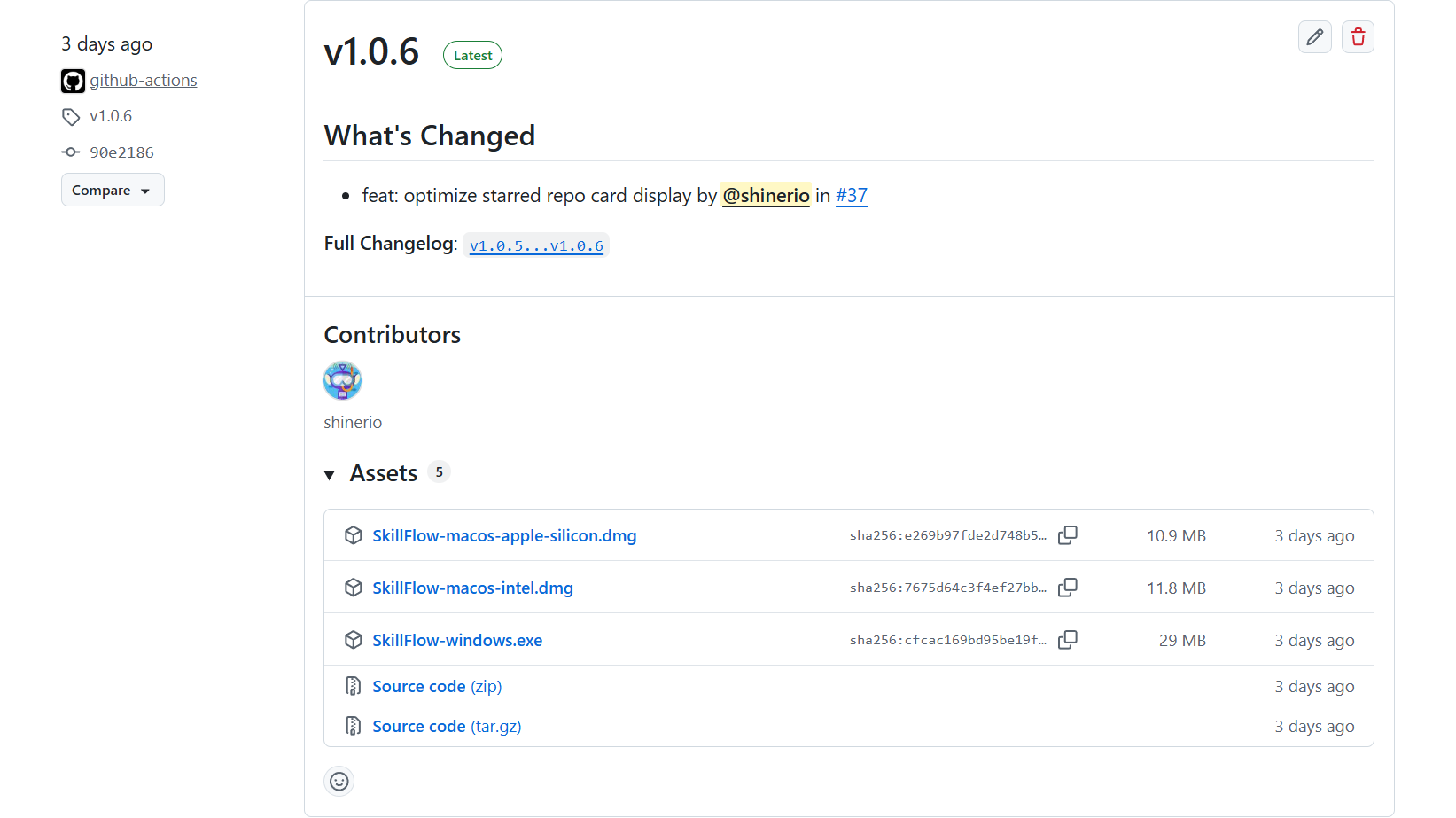
release版本发布,用户收到新版本更新消息,完成一个版本迭代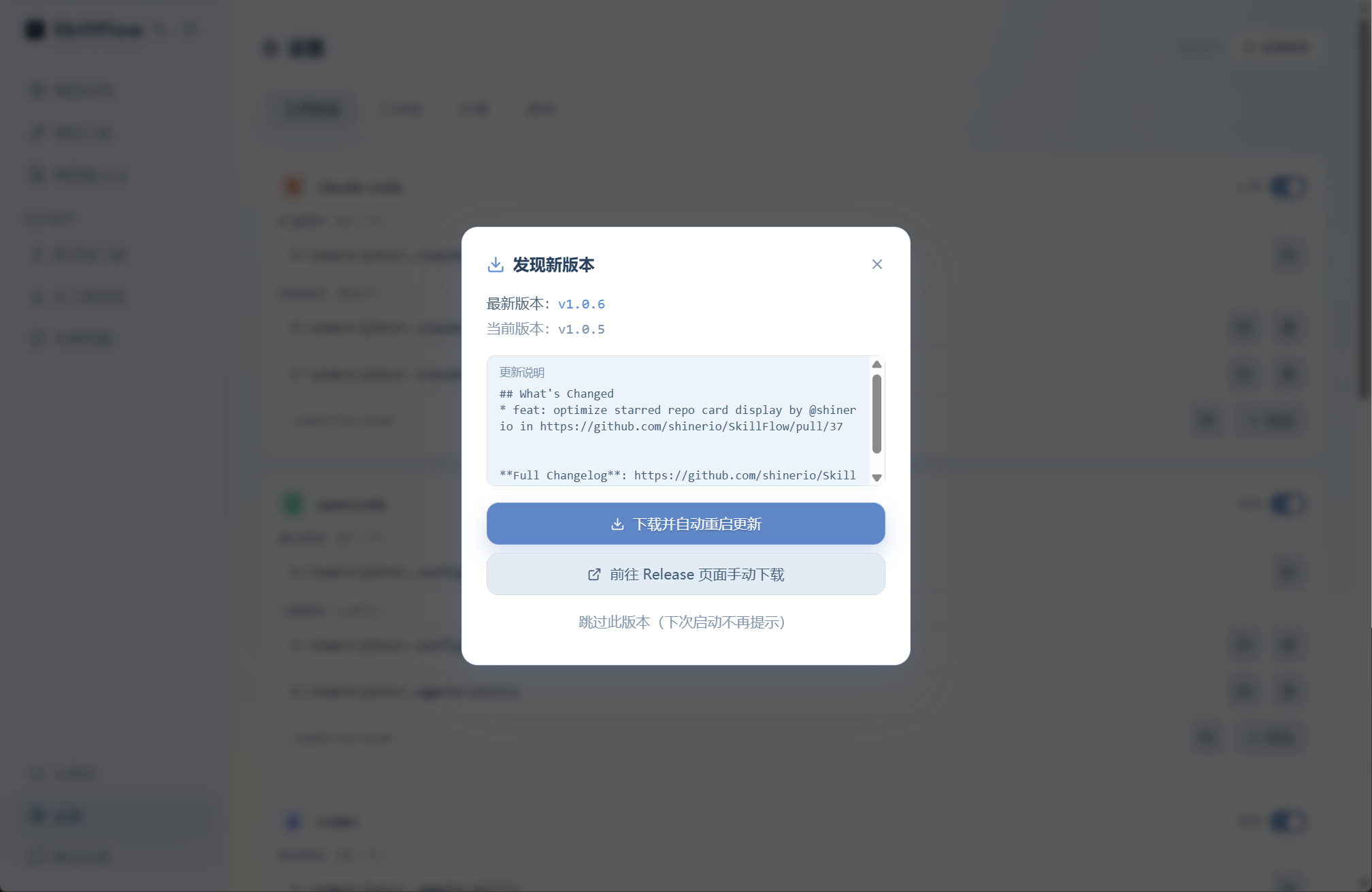
6. About SkillFlow
skillflow的项目开发动机:
- 【资产内化】 解决“收藏即遗忘”的困境。将散落于博客、视频中的碎片化skill转化为可管理、可迭代的个人资产,明确技能效用,建立淘汰与更新机制。
- 【透明掌控】 拒绝技能管理的“黑盒”状态。对海量技能按场景(编程/写作/绘图)分类归档,确保开发者对智能体能力边界拥有完全知情权与控制权。
- 【多端同步】 打破模型孤岛。针对 Claude Code、Codex、Gemini 等多智能体在特性、额度及使用场景上的差异,实现技能配置在不同智能体间的无缝同步与复用。
- 【环境一致性】 构建跨设备云同步体系。屏蔽 macOS/Windows 多设备异构环境差异,确保在任何办公场景和办公设备开发环境与技能配置的高度一致。
- 【自动迭代】 摒弃繁琐的人工维护。建立技能自动更新机制,解决来源分散导致的版本滞后问题,确保技能库时刻处于最新状态。
- 【提示词工程】 实现提示词(Prompt)的版本化管理。杜绝重复编写造成的实际效果参差不齐,推动提示词的持续优化与标准化迭代。
- 【实战驱动】 拒绝低效的重复练习(如坦克大战、个人博客、TODO)。以解决真实生产力痛点为导向,在掌握 AI 技术的同时,打造真正赋能开发的实用工具,实现“学以致用”的闭环。
7. Afterword
回头看这套工作流,我真正想解决的并不是“怎么多用几个 AI 工具”,而是三个更底层的问题:
- 如何把问题描述清楚
- 如何把上下文隔离干净
- 如何把结果验证做扎实
Linear负责承载问题,Codex负责推进实现,GitHub负责托管变更,而TDD、AI Review与CI/CD负责把主观“我觉得做完了”变成客观“这件事真的可以交付了”。工具会不断变化,但这三个原则不会变。
- 先定义问题
- 再分解复杂度
- 最后用证据闭环Note
Stop collecting, start practicing.
少囤积,多实战;少追新,多闭环
评论