1. tcp超时重传
重传机制的其中一个方式,就是在发送数据时,设定一个定时器,当超过指定的时间后,没有收到对方的ACK确认应答报文,就会重发该数据,也就是我们常说的超时重传。
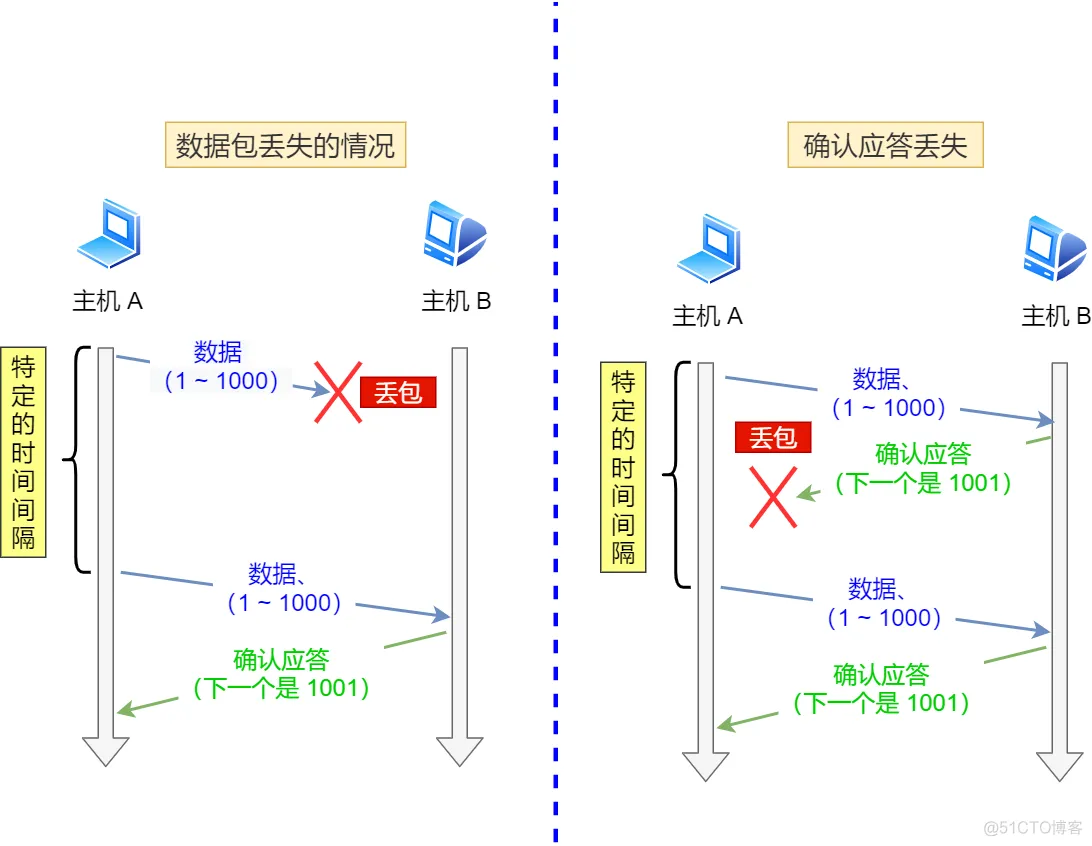
TCP 会在以下两种情况发生超时重传:
- 数据包丢失
- 确认应答丢失
1.1. RTT与RTO
- RTT(Roud Trip Time): 往返时延,从数据包发出去到接收到ACK的时间。RTT是连接粒度的,每个连接都有一个独立的RTT
- RTO(Retransmission Time Out):重传时间
!性能指标#7. 往返时间(Round-Trip Time,RTT)
超时重传时间是以 RTO (Retransmission Timeout 超时重传时间)表示。
假设在重传的情况下,超时时间 RTO 「较长或较短」时,会发生什么事情呢?
- 当超时时间 RTO 较大时,重发就慢,丢了老半天才重发,没有效率,性能差;
- 当超时时间 RTO 较小时,会导致可能并没有丢就重发,于是重发的就快,会增加网络拥塞,导致更多的超时,更多的超时导致更多的重发。
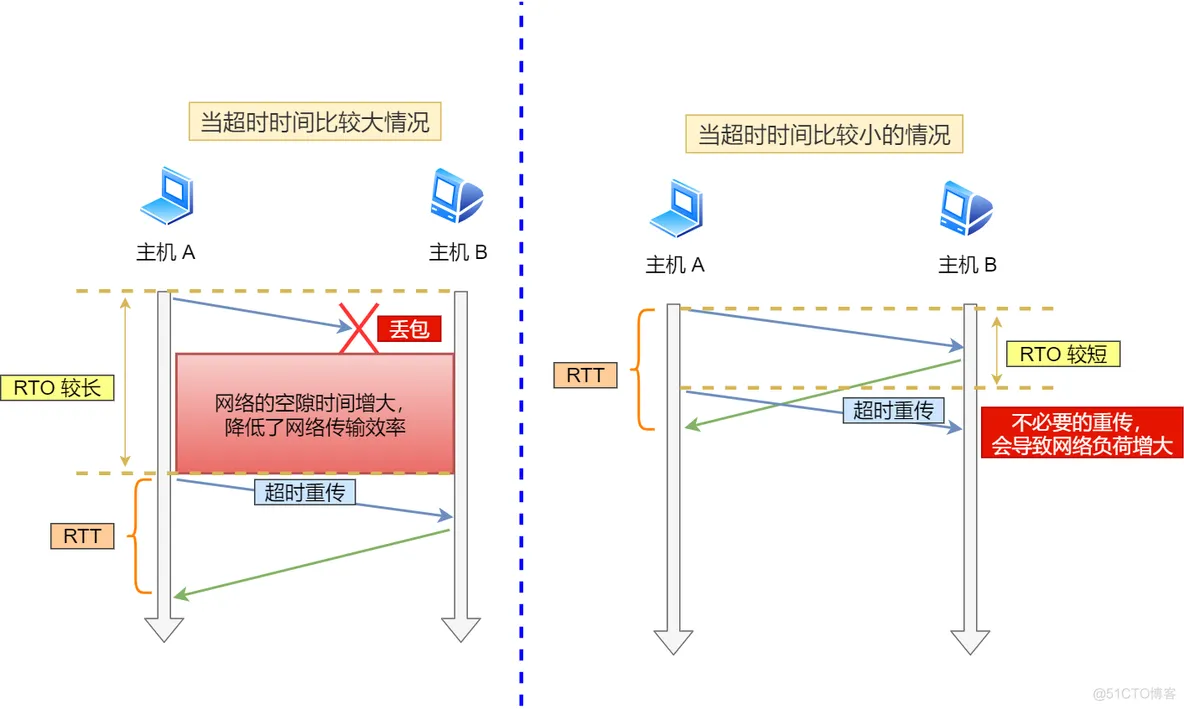
精确的测量超时时间 RTO 的值是非常重要的,这可让我们的重传机制更高效,超时重传时间 RTO 的值应该略大于报文往返 RTT 的值。
1.2. RTT经典计算方案
最初的规范RFC0793采用了加权滑动平均来估算RTT,即SRTT(Smoothed Round Trip Time)
SRTT = ( ALPHA * SRTT ) + ((1-ALPHA) * RTT)
RTO计算如下,其中UBOUND是timeout的上限(1min),LBOUND是timeout的下限(1s),ALPHA是加权因子(0.8-0.9),BETA是时延方差系数(1.3-2)
RTO = min[UBOUND,max[LBOUND,(BETA*SRTT)]]
1.2.1. 存在的问题
1.2.1.1. 二义性
RFC1122 指出当出现数据包重传的情况下,RTT的计算会出现二义性。在测量RTT样本的过程中若一个包的传输出现超时,该数据就会被重传,接着收到一条ACK信息,那么该ACK是对第一条还是第二条传输的确认就存在这二义性。对于客户端来说,它不知道发生了哪种情况,选错情况的结果就是RTT偏大/偏小,影响到RTO的计算。(最简单粗暴的解决方法就是忽略有重传的数据包,只计算那些没重传过的,但这样会导致在网络环境突然恶化的场景下,大量重传数据包没有被用来计算RTT,导致RTO无法更新,进而导致每一个分片报文都一直被重传,详见 Karn's algorithm)
1.2.1.2. 网络性能恶化加剧
RTT的加权平均算法,ALPHA系数一般都比较大,本质上是一个低通滤波器,对突然的网络波动不敏感,如果网络时延突然增加会导致实际RTT值大于预估值,导致不必要的重传,加重网络负担。
1.3. RTT最新方案
RFC6298 提出基于滑动平均值SRTT和平均偏差RTTV(Round-Trip-Time variation)来综合计算,在大数据实验的基础上通过调参得到一个控制系数K,一般为4。此外,该算法假设系统时间粒度为G秒,即差值的最小值。
- RTO设置为LOUND,即1s
- 第一个RTT(R)计算出来
SRTT=R
RTTVAR=R/2
RTO=SRTT + max(G, K * RTTVAR)
- 对于后续每一个RTT(R')
RTTVAR = (1 - beta) * RTTVAR + beta * |SRTT - R'|
SRTT = (1 - alpha) * SRTT + alpha * R'
RTO = SRTT + max(G, K * RTTVAR)
1.4. 重传机制
如果超时重发的数据,再次超时的时候,又需要重传的时候,TCP 的策略是超时间隔加倍。也就是每当遇到一次超时重传的时候,都会将下一次超时时间间隔设为先前值的两倍。tcp_retries2用于控制tcp重传的次数,若发生网络中断,预估需要15min以上才会放弃连接。
root@vultr:~# cat /proc/sys/net/ipv4/tcp_retries2
15
root@vultr:~# sysctl net.ipv4.tcp_retries2
net.ipv4.tcp_retries2 = 15
2. 快速重传
TCP 还有另外一种快速重传(Fast Retransmit)机制,它不以时间为驱动,而是以数据驱动重传。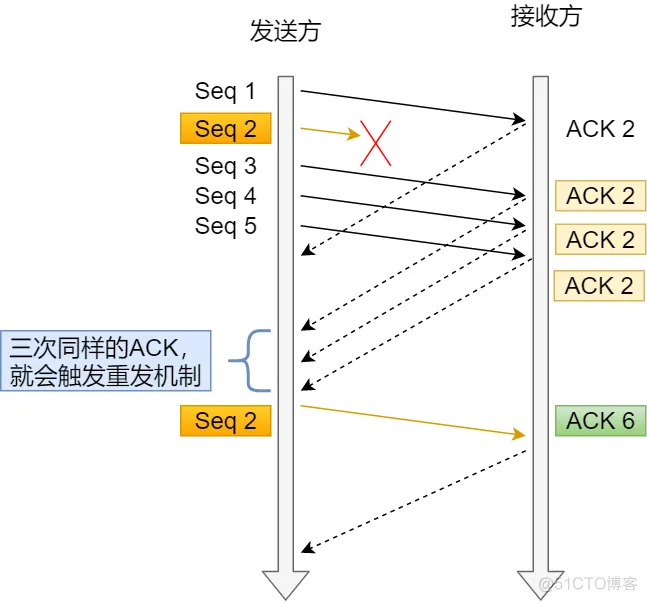
在上图,发送方发出了 1,2,3,4,5 份数据:
- 第一份 Seq1 先送到了,于是就 Ack 回 2;
- 结果 Seq2 因为某些原因没收到,Seq3 到达了,于是还是 Ack 回 2;
- 后面的 Seq4 和 Seq5 都到了,但还是 Ack 回 2,因为 Seq2 还是没有收到;
- 发送端收到了三个 Ack = 2 的确认,知道了 Seq2 还没有收到,就会在定时器过期之前,重传丢失的 Seq2。
- 最后,收到了 Seq2,此时因为 Seq3,Seq4,Seq5 都收到了,于是 Ack 回 6 。Note
快速重传的工作方式是当收到三个相同的 ACK 报文时,会在定时器过期之前,重传丢失的报文段。
3. SACK
快速重传机制只解决了一个问题,就是超时时间的问题,但是它依然面临着另外一个问题。就是重传的时候,是重传之前的一个,还是重传所有的问题。
比如对于上面的例子,是重传 Seq2 呢?还是重传 Seq2、Seq3、Seq4、Seq5 呢?因为发送端并不清楚这连续的三个Ack 2是谁传回来的,以上两种情况都是有可能的。可见,这是一把双刃剑。为了解决不知道该重传哪些 TCP 报文,于是就有 SACK 方法。
这种方式需要在 TCP 头部「选项」字段里加一个 SACK 的东西,它可以将已经接收到缓存队列的seq信息发送给发送方,这样发送方就可以知道哪些数据收到了,哪些数据没收到,知道了这些信息,就可以只重传丢失的数据。
如下图,发送方收到了三次同样的 ACK 确认报文,于是就会触发快速重发机制,通过 SACK 信息发现只有 200~299 这段数据丢失,则重发时,就只选择了这个 TCP 段进行重复。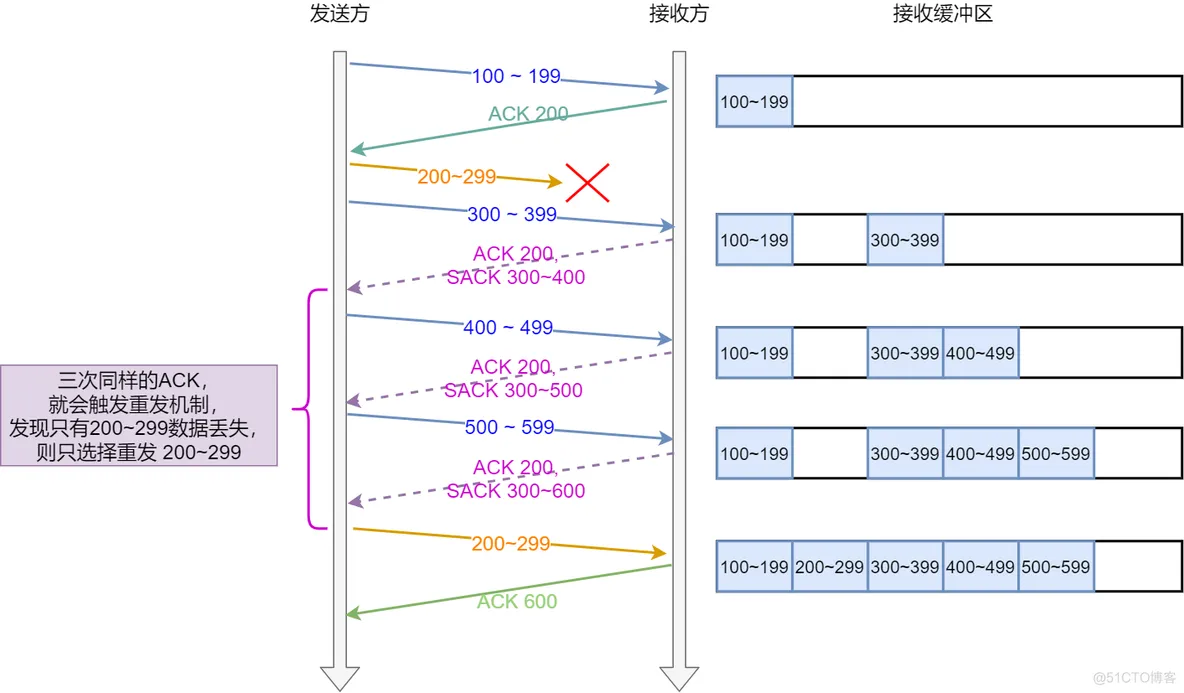
如果要支持 SACK,必须双方都要支持。在 Linux 下,可以通过 net.ipv4.tcp_sack 参数打开这个功能(Linux 2.4 后默认打开)。
root@vultr:~# sysctl net.ipv4.tcp_sack
net.ipv4.tcp_sack = 1
4. Duplicate SACK
Duplicate SACK 又称 D-SACK,其主要使用了SACK来告诉「发送方」有哪些数据被重复接收了。
sack表现是ack小与sack,代表丢数据了,但是我可以提前ack后面的;D-sack表现是ack大于sack,说明数据重复了,你发给我的数据我已经ack过了。
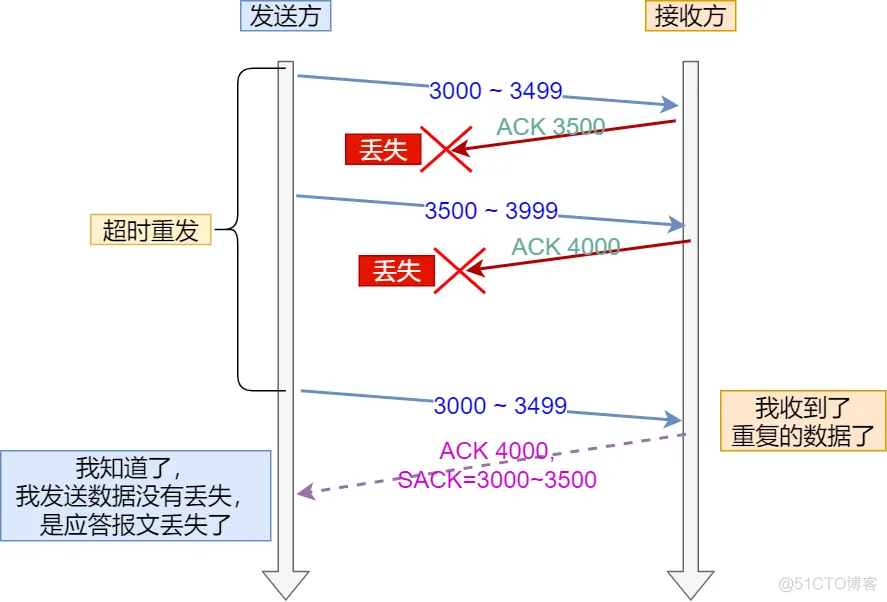
4.1. ACK丢包
- 「接收方」发给「发送方」的两个 ACK 确认应答都丢失了,所以发送方超时后,重传第一个数据包(3000 ~ 3499)
- 「接收方」发现数据是重复收到的,于是回了一个 SACK = 3000
3500,告诉「发送方」 30003500 的数据早已被接收了,因为ACK都到了 4000 了,已经意味着 4000之前的所有数据都已收到,所以这个 SACK 就代表着D-SACK。 - 这样「发送方」就知道了,数据没有丢,是「接收方」的 ACK 确认报文丢了。
4.2. 网络时延
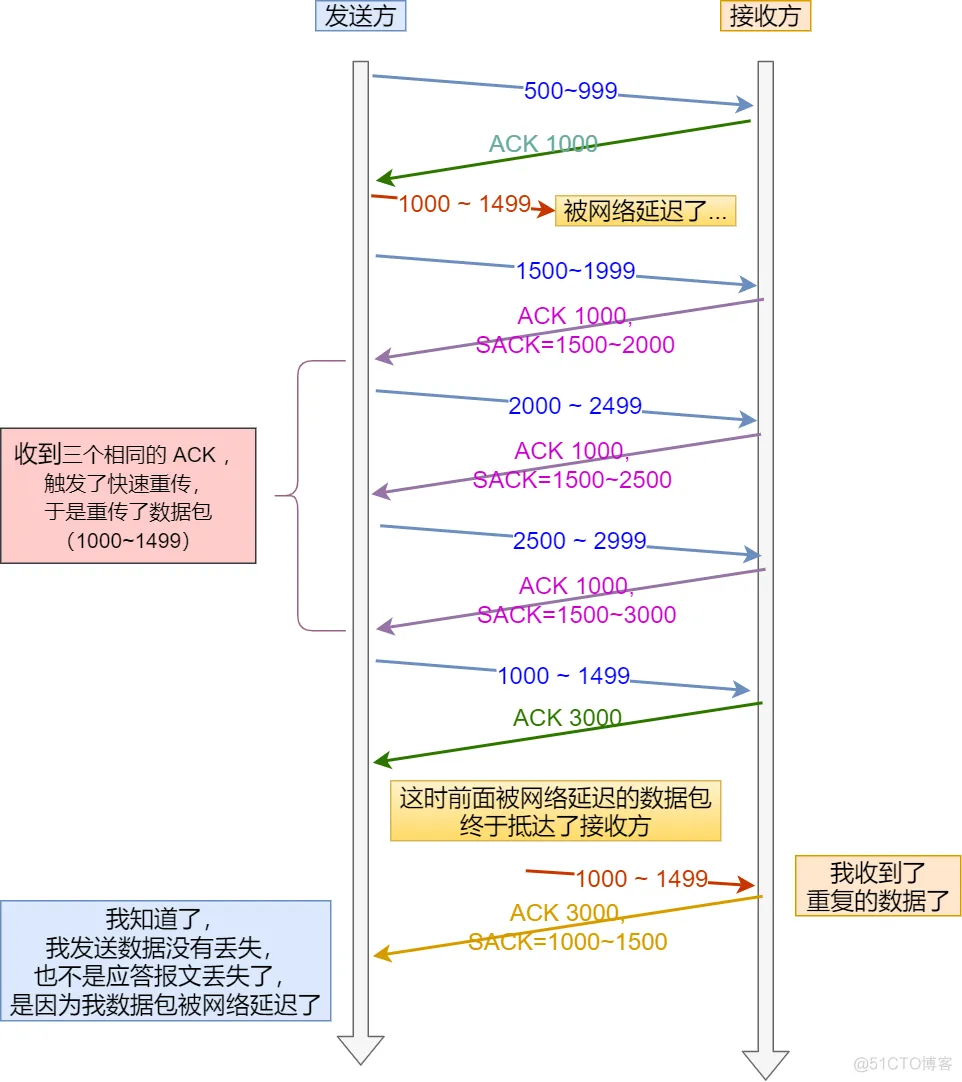
- 数据包(1000~1499) 被网络延迟了,导致「发送方」没有收到 Ack 1500 的确认报文。
- 而后面报文到达的三个相同的 ACK 确认报文,就触发了快速重传机制,但是在重传后,被延迟的数据包(1000~1499)又到了「接收方」;
- 所以「接收方」回了一个 SACK=1000~1500,因为 ACK 已经到了 3000,所以这个 SACK 是 D-SACK,表示收到了重复的包。
- 这样发送方就知道快速重传触发的原因不是发出去的包丢了,也不是因为回应的 ACK 包丢了,而是因为网络延迟了。
4.3. 优势
在TCP重传场景下,Duplicate SACK (D-SACK) 是TCP选择性确认 (SACK) 机制的一个扩展,具有以下重要作用:
- 检测重复数据包接收:D-SACK允许接收方通知发送方它收到了重复的数据段,无论这些重复段是否在接收方的当前接收窗口内。
- 区分网络问题类型:
- 帮助发送方区分是网络延迟导致的数据包重排,还是数据包丢失
- 区分数据包被网络复制还是发送方重传导致的重复
- 改进拥塞控制:
- 通过正确识别非拥塞丢包情况,避免不必要的拥塞窗口缩小
- 当重复包是由网络延迟而非丢包引起时,可以避免错误的重传超时调整
- 优化重传策略:
- 减少不必要的重传,提高网络带宽利用率
- 允许更精确地计算往返时间(RTT)
- 提高网络性能:
- 特别是在无线网络等高丢包环境中效果显著
- 减少由于错误解读网络状况而导致的性能下降
D-SACK是在RFC 2883中定义的,它通过允许接收方报告重复收到的数据段,使TCP协议能够更智能地应对网络中的各种异常情况,从而提高网络传输效率和可靠性。Note在 Linux 下可以通过
net.ipv4.tcp_dsack参数开启/关闭这个功能(Linux 2.4 后默认打开)
5. tcp user timeout
可以针对不同应用设置超时时间,当数据发送超过设置时间后仍然没有ack,或者迟迟读不到数据,就放弃链接。tcp user timouet可以使用setsockopt函数实现。
<span class="tag">#include</span> <sys/socket.h>
int setsockopt(int sockfd, int level, int optname, const void *optval, socklen_t optlen);
- sockfd:套接字描述符,指定要设置选项的套接字。
- level:协议级别,指定选项所在的协议层。常见值包括:
SOL_SOCKET:套接字层级选项IPPROTO_TCP:TCP协议选项IPPROTO_IP:IP协议选项IPPROTO_IPV6:IPv6协议选项
- optname:选项名称,指定要设置的特定选项。不同协议层有不同的选项,例如:
SO_REUSEADDR、SO_KEEPALIVE(套接字层)TCP_NODELAY、TCP_USER_TIMEOUT(TCP层)IP_TTL(IP层)
- optval:选项值的指针,指向包含新选项值的缓冲区。
- optlen:
optval缓冲区的大小(以字节为单位)。
5.1. 控制tcp连接超时时间
具体来说,TCP_USER_TIMEOUT定义了TCP在放弃连接之前等待未确认数据的最长时间。当一个TCP连接已经建立,并且发送方发送了数据但长时间没有收到确认(ACK)时,这个参数决定了发送方等待多久后认为连接失效。
- 不控制建立连接的超时:TCP 连接建立(三次握手)的超时通常由系统内核参数如
tcp_syn_retries控制,或者在应用程序中通过connect()调用的超时机制控制。 - 控制数据传输过程中的超时:当连接已建立,并且有未确认的数据时才生效。
int timeout = 30000; // 30秒(毫秒为单位)
setsockopt(sockfd, IPPROTO_TCP, TCP_USER_TIMEOUT, &timeout, sizeof(timeout));
5.2. 用途
主要用于检测网络异常导致的对端无响应情况,特别是在长连接应用中,可以更早地检测到连接断开,而不是一直等待TCP的默认重传机制耗尽,在java应用中可以通过设置数据库关键配置#1. socketTimeout|socketTimeout控制。
评论