- RocketMQ 的存储结构相对较为灵活,可以针对不同的场景进行优化。它采用了单一的 commitlog 文件来顺序存储所有消息,然后通过索引文件快速定位特定topic的消息。这种设计使得在处理大量 topic 时,存储资源的分配更加高效。每个topic都对应独立索引文件,加上page cache机制,所以读的性能也不差。
kafka的问题
- Topic 及 Topic 分区总量不断增加,集群性能受到影响:Kafka 高性能依赖于磁盘的顺序读写,磁盘上大量分区导致随机读写加重;
- 业务流量增加迅速,存量集群变大,需要将老的业务进行资源组隔离迁移或者集群拆分。无论是资源组隔离还是集群的隔离的方式,由于集群不可以进行动态扩缩容,机器不能够进行灵活调配,都存在利用率不高、运维成本增加的问题;
- 机器扩容慢,需要做长时间流量均衡,难以应对突发流量。集群规模越大,问题越突出;
- 消费端性能扩展太依赖分区扩容,导致集群元数据疯狂增长;
- 集群数量对应的机器基数大,硬件故障概率高,出现硬件故障时影响会直接传导到客户端,缺少中间层容错。
Pulsar 采用计算存储层分离架构。计算层的 Broker 节点是对等且无状态的,可以快速扩展;存储层使用BookKeeper作为节点,同样节点对等。这种分离架构支持计算和存储层各自独立扩展。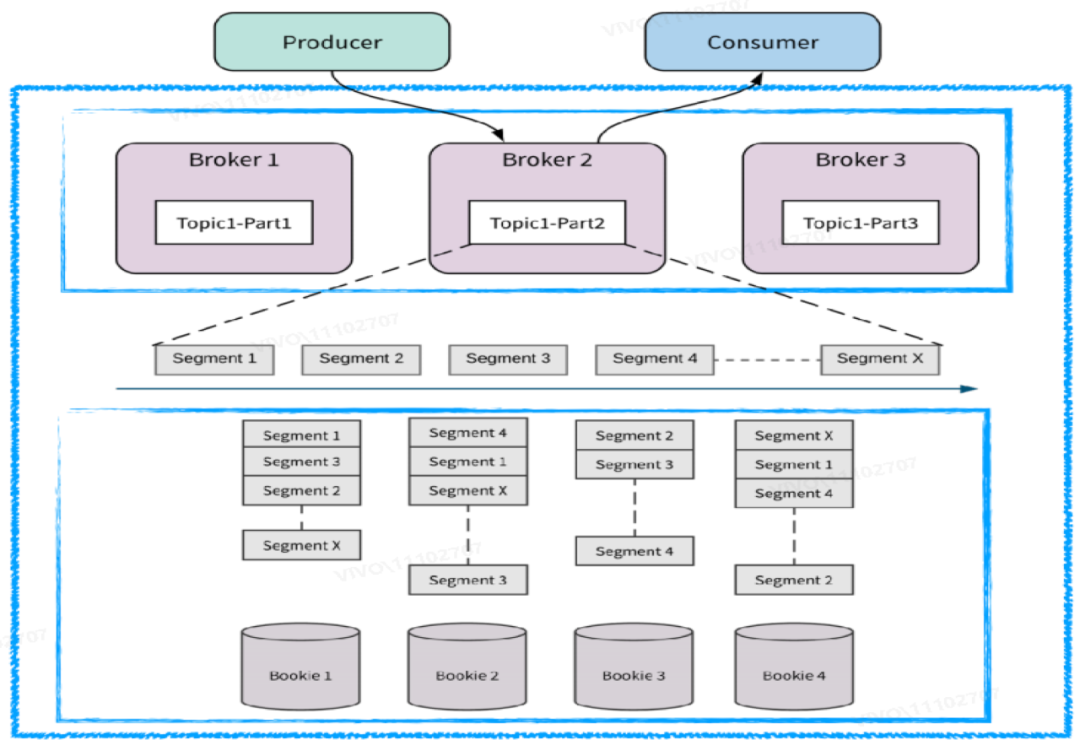
其次,Pulsar 的各个节点都是轻量化的,在出现故障和宕机时可以快速恢复。一般情况下可以通过快速上下线来解决某个节点机器的问题。同时 Broker 层可以作为 BookKeeper 层的容错层,可以防止故障直接传导至用户端。
构建下一代万亿级云原生消息架构:Apache Pulsar 在 vivo 的探索与实践_大数据_陈建波_InfoQ精选文章
评论