1. 分布式公平锁
ZooKeeper的临时顺序节点,天生就有一副实现分布式锁的胚子。
ZooKeeper的每一个节点,都是一个天然的顺序发号器。 在每一个节点下面创建临时顺序节点(EPHEMERAL_SEQUENTIAL)类型,新的子节点后面,会加上一个次序编号,而这个生成的次序编号,是上一个生成的次序编号加一。 例如,有一个用于发号的节点“/test/lock”为父亲节点,可以在这个父节点下面创建相同前缀的临时顺序子节点,假定相同的前缀为“/test/lock/seq-”。第一个创建的子节点基本上应该为/test/lock/seq-0000000000,下一个节点则为/test/lock/seq-0000000001,依次类推。
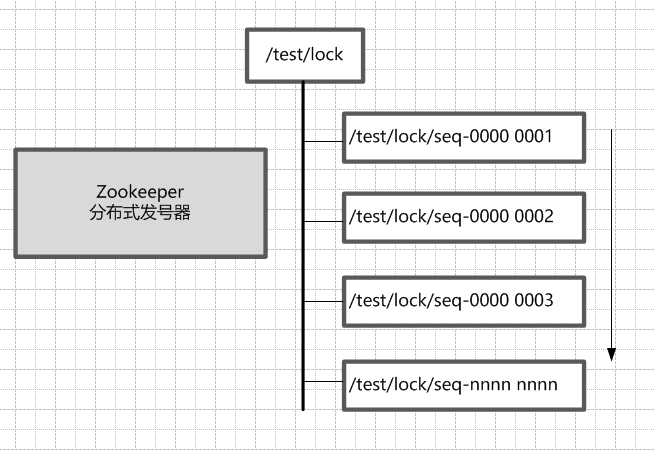
ZooKeeper节点的递增有序性,可以确保锁的公平 一个ZooKeeper分布式锁,首先需要创建一个父节点,尽量是持久节点(PERSISTENT类型),然后每个要获得锁的线程,都在这个节点下创建个临时顺序节点。由于ZK节点,是按照创建的次序,依次递增的。 为了确保公平,可以简单的规定:编号最小的那个节点,表示获得了锁。所以,每个线程在尝试占用锁之前,首先判断自己是排号是不是当前最小,如果是,则获取锁。
ZooKeeper的节点监听机制,可以保障占有锁的传递有序而且高效。每个线程抢占锁之前,先尝试创建自己的ZNode。同样,释放锁的时候,就需要删除创建的Znode。创建成功后,如果不是排号最小的节点,就处于等待通知的状态。等谁的通知呢?不需要其他人,只需要等前一个Znode 的通知就可以了。前一个Znode删除的时候,会触发Znode事件,当前节点能监听到删除事件,就是轮到了自己占有锁的时候。第一个通知第二个、第二个通知第三个,击鼓传花似的依次向后。 ZooKeeper的节点监听机制,能够非常完美地实现这种击鼓传花似的信息传递。具体的方法是,每一个等通知的Znode节点,只需要监听(linsten)或者监视(watch)排号在自己前面那个,而且紧挨在自己前面的那个节点,就能收到其删除事件了。 只要上一个节点被删除了,就进行再一次判断,看看自己是不是序号最小的那个节点,如果是,自己就获得锁。
2. 锁异常释放
ZooKeeper的内部优越的机制,能保证由于网络异常或者其他原因,集群中占用锁的客户端失联时,锁能够被有效释放。一旦占用Znode锁的客户端与ZooKeeper集群服务器失去联系,这个临时Znode也将自动删除。排在它后面的那个节点,也能收到删除事件,从而获得锁。正是由于这个原因,在创建取号节点的时候,尽量创建临时znode节点
3. 避免羊群效应
ZooKeeper的节点监听机制,能避免羊群效应 ZooKeeper这种首尾相接,后面监听前面的方式,可以避免羊群效应。所谓羊群效应就是一个节点挂掉,所有节点都去监听,然后做出反应,这样会给服务器带来巨大压力,所以有了临时顺序节点,当一个节点挂掉,只有它后面的那一个节点才做出反应。
zk里有一把锁,这个锁就是zk上的一个节点。然后呢,两个客户端都要来获取这个锁。假设客户端A抢先一步,对zk发起了加分布式锁的请求,这个加锁请求是用到了zk中的一个特殊的概念,叫做“临时顺序节点”。 简单来说,就是直接在”my_lock”这个锁节点下,创建一个顺序节点,这个顺序节点有zk内部自行维护的一个节点序号。客户端A发起一个加锁请求 比如说,第一个客户端来搞一个顺序节点,zk内部会给起个名字叫做:xxx-000001。然后第二个客户端来搞一个顺序节点,zk可能会起个名字叫做:xxx-000002,最后一个数字都是依次递增的,从1开始逐次递增。zk会维护这个顺序。 所以这个时候,假如说客户端A先发起请求,就会搞出来一个顺序节点,Curator框架大概会弄成如下的样子: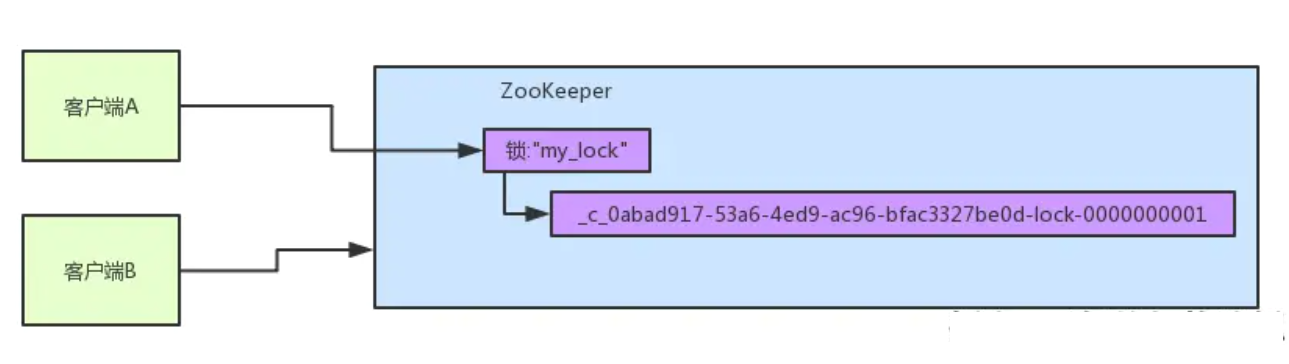
客户端A发起一个加锁请求,先会在你要加锁的node下搞一个临时顺序节点,这一大坨长长的名字都是Curator框架自己生成出来的。 然后,那个最后一个数字是”1″。因为客户端A是第一个发起请求的,所以给他搞出来的顺序节点的序号是”1″。 接着客户端A创建完一个顺序节点。还没完,他会查一下”my_lock”这个锁节点下的所有子节点,并且这些子节点是按照序号排序的,这个时候他大概会拿到这么一个集合:
接着客户端A会走一个关键性的判断,就是说:唉!兄弟,这个集合里,我创建的那个顺序节点,是不是排在第一个啊? 如果是的话,那我就可以加锁了啊!因为明明我就是第一个来创建顺序节点的人,所以我就是第一个尝试加分布式锁的人啊! bingo!加锁成功!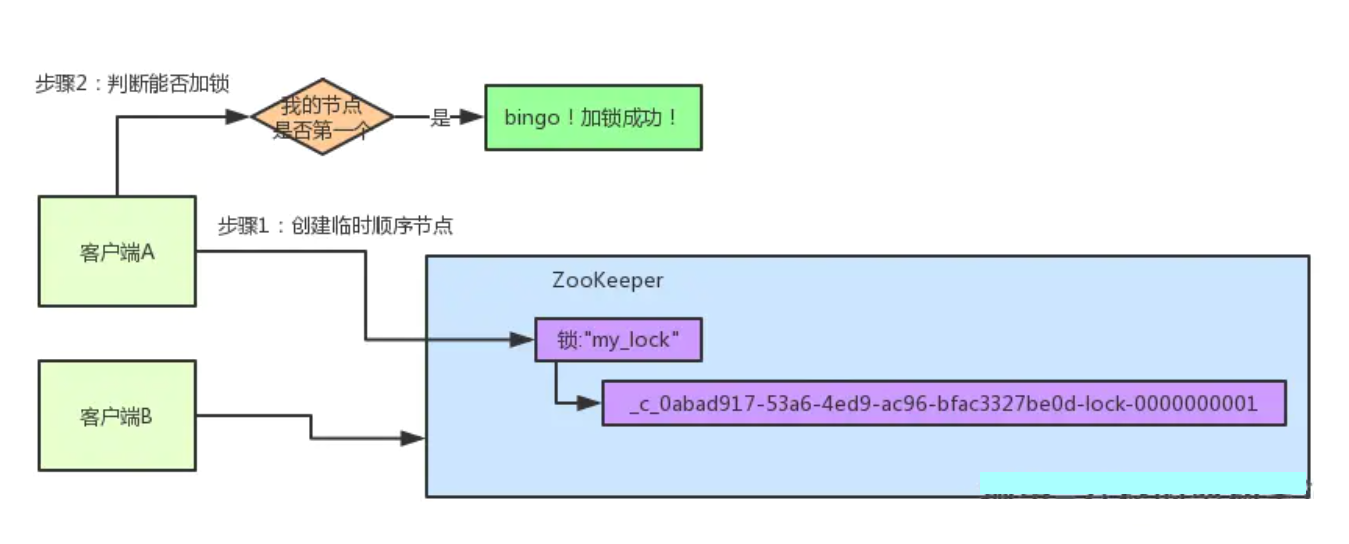
客户端B过来排队 接着假如说,客户端A都加完锁了,客户端B过来想要加锁了,这个时候他会干一样的事儿:先是在”my_lock”这个锁节点下创建一个临时顺序节点,此时名字会变成类似于:
看看下面的图: 客户端B因为是第二个来创建顺序节点的,所以zk内部会维护序号为”2″。 接着客户端B会走加锁判断逻辑,查询”my_lock”锁节点下的所有子节点,按序号顺序排列,此时他看到的类似于:
客户端B因为是第二个来创建顺序节点的,所以zk内部会维护序号为”2″。 接着客户端B会走加锁判断逻辑,查询”my_lock”锁节点下的所有子节点,按序号顺序排列,此时他看到的类似于: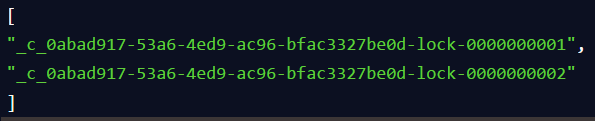
同时检查自己创建的顺序节点,是不是集合中的第一个? 明显不是啊,此时第一个是客户端A创建的那个顺序节点,序号为”01″的那个。所以加锁失败! 客户端B开启监听客户端A 加锁失败了以后,客户端B就会通过ZK的API对他的顺序节点的上一个顺序节点加一个监听器。zk天然就可以实现对某个节点的监听。 他的上一个顺序节点,不就是下面这个吗?
他的上一个顺序节点,不就是下面这个吗?  即客户端A创建的那个顺序节点! 所以,客户端B会对:
即客户端A创建的那个顺序节点! 所以,客户端B会对:  这个节点加一个监听器,监听这个节点是否被删除等变化!大家看下面的图。
这个节点加一个监听器,监听这个节点是否被删除等变化!大家看下面的图。  接着,客户端A加锁之后,可能处理了一些代码逻辑,然后就会释放锁。那么,释放锁是个什么过程呢? 其实很简单,就是把自己在zk里创建的那个顺序节点,也就是:
接着,客户端A加锁之后,可能处理了一些代码逻辑,然后就会释放锁。那么,释放锁是个什么过程呢? 其实很简单,就是把自己在zk里创建的那个顺序节点,也就是:  这个节点给删除。 删除了那个节点之后,zk会负责通知监听这个节点的监听器,也就是客户端B之前加的那个监听器,说:兄弟,你监听的那个节点被删除了,有人释放了锁。
这个节点给删除。 删除了那个节点之后,zk会负责通知监听这个节点的监听器,也就是客户端B之前加的那个监听器,说:兄弟,你监听的那个节点被删除了,有人释放了锁。  此时客户端B的监听器感知到了上一个顺序节点被删除,也就是排在他之前的某个客户端释放了锁。 客户端B抢锁成功 此时,就会通知客户端B重新尝试去获取锁,也就是获取”my_lock”节点下的子节点集合,此时为:
此时客户端B的监听器感知到了上一个顺序节点被删除,也就是排在他之前的某个客户端释放了锁。 客户端B抢锁成功 此时,就会通知客户端B重新尝试去获取锁,也就是获取”my_lock”节点下的子节点集合,此时为:  集合里此时只有客户端B创建的唯一的一个顺序节点了! 然后呢,客户端B判断自己居然是集合中的第一个顺序节点,bingo!可以加锁了!直接完成加锁,运行后续的业务代码即可,运行完了之后再次释放锁。
集合里此时只有客户端B创建的唯一的一个顺序节点了! 然后呢,客户端B判断自己居然是集合中的第一个顺序节点,bingo!可以加锁了!直接完成加锁,运行后续的业务代码即可,运行完了之后再次释放锁。 
评论