时间轮(Timing Wheel)是George Varghese和Tony Lauck在1996年的论文Hashed and Hierarchical Timing Wheels: data structures to efficiently implement a timer facility实现的,是一种实现延迟功能(定时器)的精妙的高级算法,其算法应用范围非常广泛它在Linux内核中使用广泛,是Linux内核定时器的实现方法和基础之一,在Java开发过程中常用的Dubbo、Netty、Akka、Quartz、ZooKeeper 、Kafka等各种框架中也都有应用。
1. 解决问题场景
如果一个系统中存在着大量的调度任务,而大量的调度任务如果每一个都使用自己的调度器来管理任务的生命周期的话,浪费cpu的资源并且很低效。
时间轮是一种高效来利用线程资源来进行批量化调度的一种调度模型。把大批量的调度任务全部都绑定到同一个的调度器上面,使用这一个调度器来进行所有任务的管理(manager),触发(trigger)以及运行(runnable)。能够高效的管理各种延时任务,周期任务,通知任务等等
2. 单级时间轮
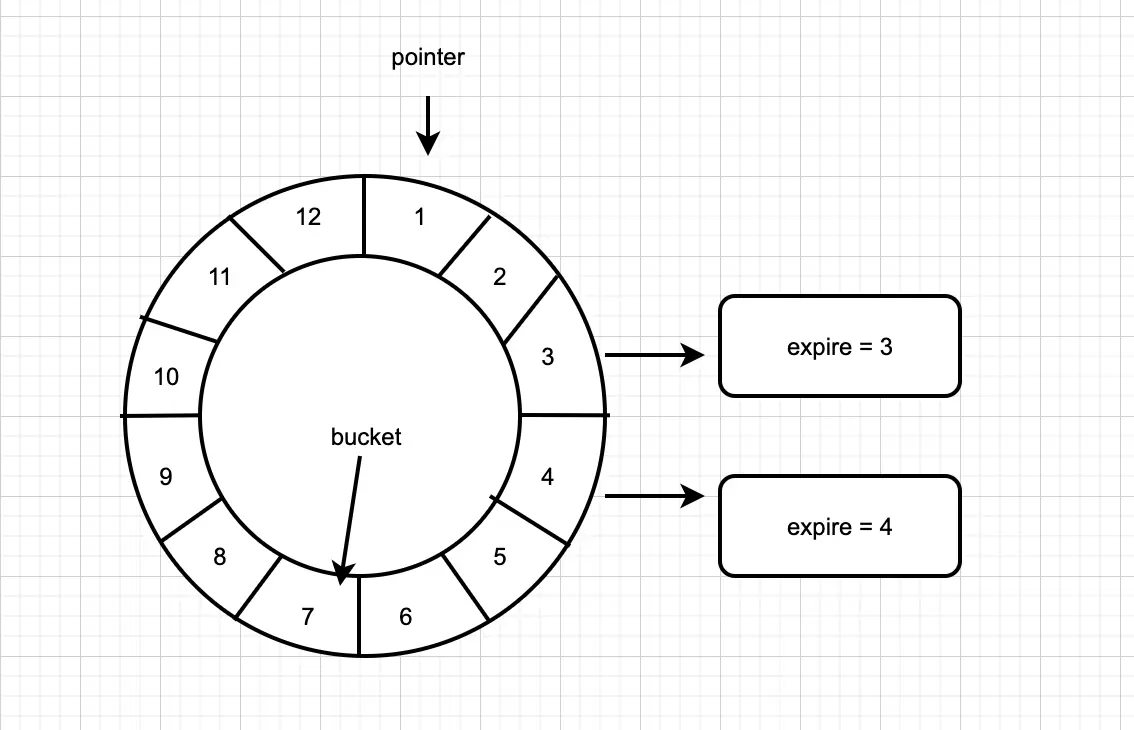
2.1. 基础概念
- tick:时间轮的总大小,上图为12
- interval: 时间轮的间隔,上图为1
2.2. 数据结构设计
- 时间轮是一个环形队列,底层通过数组实现,数组中的每个元素可以存放个定时任务列表(HashedWheelBucket)
- 数组中的每个元素(HashedWheelBucket)是一个双向链表
- 链表中的每一个节点存储了真正的任务
关键对象如下:
- pointer : 指针,随着时间的推移,指针不停地向前移动,到12后再回到1。
- bucket : 时间轮由bucket组成,如上图,有12个bucket。每个bucket都挂载了未来要到期的节点(即: 定时任务/延时任务)。
- interval:两个相邻的bucket的时间间隔
时间轮使用一个表盘指针(pointer),用来表示时间轮当前指针跳动的次数,可以用interval * (pointer + 1)来表示下一次到期的任务,需要处理此时间格(bucket)所对应的所有任务
2.3. 时间复杂度
时间轮的tick与数据量无关,通过数组下标可以直接访问,指定任务插入指定slot的时间复杂度是o(1),每个slot上的双向链表上的所有任务理论上都是一起处理的,会交给异步线程执行,因此删除指定slot的时间复杂度是0(1)。
2.4. 存在的问题
显而易见,时间轮算法解决了遍历效率低的问题。(现在,即使有 10k 个任务,轮询线程也不必每轮遍历10k个任务,而仅仅需要遍历24个时间刻度)。时间轮算法中,轮询线程遍历到某一个时间刻度后,总是执行对应刻度上任务队列中的所有任务(通常是将任务扔给异步线程池来处理),而不再需要遍历检查所有任务的时间戳是否达到要求。
2.4.1. 内存问题
时间轮算法的精度取决于时间段“指针”单元的最小粒度大小,比如时间轮的格子是一秒跳一次,那么调度精度小于一秒的任务就无法被时间轮所调度。另外,如果保持精度不变,但是延迟任务需要在300秒后执行,轮盘总刻度也得达到300以上。为了实现这两点目的,我们只能通过扩充bucket的范围来实现。例如,将bucket设置成 2^32个,但是这样会带来巨大的内存消耗。在时间刻度密集,任务数少的情况下,大部分时间刻度所占用的内存空间是没有任何意义的。
2.4.2. 效率问题
当时间刻度增多,而任务数较少时,轮询线程的遍历效率会下降,例如,如果只有50个时间刻度上有任务,但却需要遍历1440个时间刻度。这违背了我们提出时间轮算法的初衷:解决遍历轮询线程遍历效率低的问题。
3. 带round的单级时间轮
时间轮的时间刻度随着时间精度而增加并不是一个好的问题解决思路,所以计划将时间轮的精度设置为秒,时间刻度个数固定为60。每一个任务拥有一个round字段,基于单时间轮原理之下,我们在每个bucket块下的链表的节点需要多存储一个新字段round。
当指针转到某个bucket时,不能像简单的单时间轮那样直接执行bucket下所有的定时器,而是要去遍历该bucket下的链表,判断判断时间轮转动的次数是否等于节点中的round值,只有当expire和round都相同的情况下,才能执行该任务。如当前时间点为1,设置一个14秒后到期的定时任务,则slot位置为(14 + 1) % 12 = 3,round = ceiling[14 / 12] = 2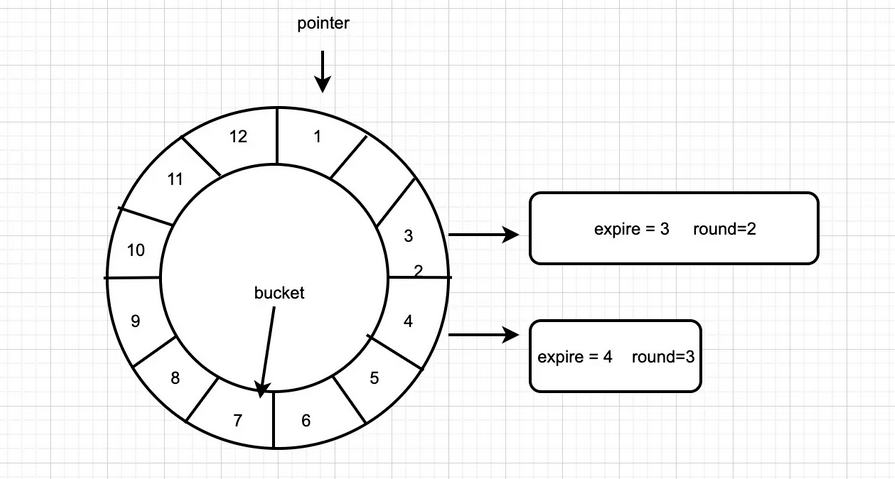
轮询线程的执行逻辑是每隔一秒处理一个时间刻度上任务队列中的所有任务,任务的 round字段减 1,接着判断如果round字段的值变为 0,那么将任务移出任务队列,交给异步线程池来执行对应任务。如果是重复执行任务,那么再将任务添加到任务队列中。
3.1. 存在的问题
改进版单时间轮是时间和空间折中的方案,由于需要遍历单个buket上的链表,因此不像单时间轮那样有O(1)的时间复杂度。但是也不会像单时间轮那样,为了满足需求产生大量的bucket,在空间上有一定优化。因此虽然简化了时间轮的刻度个数,但是并没有简化运行效率不高的问题。
改进版的时间轮如果某个bucket上挂载的定时器特别多,那么需要花费大量的时间去遍历这些节点,如果bucket下的链表每个节点的round都不相同,那么一次遍历下来可能只有极少数的定时器需要立刻执行的,因此很难在时间和空间上都达到理想效果。
时间轮每次处理一个时间刻度,就需要处理其上任务队列的所有任务。其运行效率甚至与基于普通任务队列实现的定时任务框架没有区别。
4. 层级时间轮
为了解决单时轮和轮数时间轮引起的性能问题和资源问题的另一种方式是在层次结构中使用多个定时轮,由多个层级来进行多次hash进行任务数据的传递,从而减少对应的时间和空间的复杂程度。就像钟表一样,秒针转一圈,分针转一格,通过小轮驱动大轮,小轮上的任务到时间后会被放到比它大一级的轮上,任务只会在最大的那个轮上被执行。
4.1. 优点
- 轮询线程效率变高:首先不再需要计算round值,其次任务队列中的任务一旦被遍历,就是需要被处理的(没有空轮询问题)
- 线程并发性好:虽然引入了并发线程,但是线程数仅仅和时钟轮的级数有关,并不随着任务数的增多而改变。
- 如果任务按照分钟级别来定时执行,那么当分钟时间轮达到对应刻度时,就会将任务交给异步线程来处理,然后将任务再次注册到秒级别的时钟轮上。
5. 时间轮在network中的应用
network中packet的生命周期管理常使用时间轮,主要有以下几方面原因:
- 高效性
- 低时间复杂度:时间轮算法能将插入和删除操作的时间复杂度降为 O (1)。在处理大量网络包时,能快速地添加或删除与包相关的定时任务,如设置包的超时重传、存活时间、会话的老化时间等,相比基于无序队列(插入 O (1),遍历 O (n))或有序队列(插入 O (log n))的计时器实现方式,性能优势明显。
- 批量处理任务:可以将大量与包生命周期管理相关的任务绑定到时间轮上,通过时间轮的指针转动,批量地触发和执行到期任务。比如,在同一时间格内的多个包(或会话)的超时任务可以一次性处理,减少了逐个检查和处理任务的开销。
- 资源管理优势
- 减少线程分配:能高效利用线程资源,只需一个或少数几个线程来管理时间轮,负责推动指针和执行到期任务,避免了为每个包的生命周期管理任务都分配一个单独的线程或调度器,从而降低了 CPU 的负载和资源浪费。
- 内存占用可控:通过合理设置时间轮的刻度和轮次等参数,可以在满足包生命周期管理需求的同时,有效地控制内存占用。例如,采用多层时间轮结构,能在保证时间精度的前提下,用较少的空间存储大量不同超时时间的任务。
- 灵活性与可扩展性
- 适应不同场景:可以根据网络应用的具体需求,灵活调整时间轮的参数,如时间刻度的大小、轮的层数、任务队列的长度等,以适应不同的网络环境和包处理要求。比如,在实时性要求较高的网络应用中,可设置较小的时间刻度;在对时间精度要求不高但需要处理大量包的场景下,可适当增大时间刻度以减少资源消耗。
- 易于扩展功能:便于与其他网络功能和算法集成,进行功能扩展。例如,可以与网络拥塞控制算法结合,根据网络拥塞情况动态调整包的超时时间;也可以与流量控制算法配合,对不同优先级的包设置不同的生命周期管理策略。
- 时间管理特性
- 精确控制包的生命周期:能为每个包精确地设置生存时间、超时时间等,确保包在网络中按照预期的时间规则进行传输、处理和销毁。比如,对于实时性要求高的视频流数据包,可设置较短的超时时间,及时重传丢失的包,保证视频播放的流畅性;对于一些非关键的控制信息包,可设置相对较长的生存时间,以适应网络的不确定性。
- 处理周期性任务:方便处理与包相关的周期性任务,如定期发送心跳包、定期更新包的状态信息等。通过在时间轮上设置周期性的任务节点,能够自动、按时触发这些任务,无需额外的复杂定时机制。
评论