- 为什么需要消息队列
- 消息队列的核心设计和使用
- 深入消息队列高性能原理
cap原则
1. 为什么需用消息队列
1.1. 业务解耦
业务解耦,代码解耦。现在的云网络服务大都遵循SDN设计思想,将服务拆分成管控转三部分,不同组件负责承载不同的业务,其解耦方式之一就是通过消息队列。很多消息队列都叫broker,即代理,其实就很好的表现了消息队列的功能。
1.2. 广播
消息队列的基本功能之一是进行广播。如果没有消息队列,每当一个新的业务方出现,我们都要联调一次新接口。有了消息队列,我们只需要关心消息是否送达了队列,至于谁希望订阅,是下游的事情,无疑极大地减少了开发和联调的工作量。如VPC作为网络的底座,其port的创删改消息被很多其他网络服务关注,如果不通过消息队列进行广播,那么VPC的port相关业务将会变得非常臃肿。
1.3. 同步变异步
有些RPC场景不需要进行同步调用,可以通过同步变异步方式加快响应速度。比如网络服务,管理面资源创删改到数据面生效往往需要很长时间,如果不通过消息队列进行解耦,那么用户的API体验将会非常糟糕,接口超时会变成常态。
1.4. 流量削峰
消息中间件提供的核心之一为消息队列,可堆积大量的消息。在我们的整个云网络架构中,不同的云服务组件具有不同的性能,当上游系统的吞吐能力远高于下游系统,在流量洪峰时可能会冲垮下游系统。而通过消息中间件可以在峰值时堆积消息,在峰值过去后下游系统慢慢消费。
1.5. 可恢复性
即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
2. 常见的消息队列形式
- 内存存储,如quark底座采用的akka框架就使用了MailBox来实现API请求的排队。
- 持久化存储,如kafka、rabbitMQ、rocketMQ。
3. 消息队列的核心设计
3.1. 消息保序
消息的保序性可以分为两部分,生产有序和消费有序。消息对于消息队列来说是透明的,不会理解消息谁前谁后,所以生产的有序性一般需要业务来保证,一般可以通过对资源加锁来控制资源不会并发操作,因此下文我们主要讨论消费有序。
3.1.1. 多队列模型
如果队列有多个的情况下,无法保证全局有序。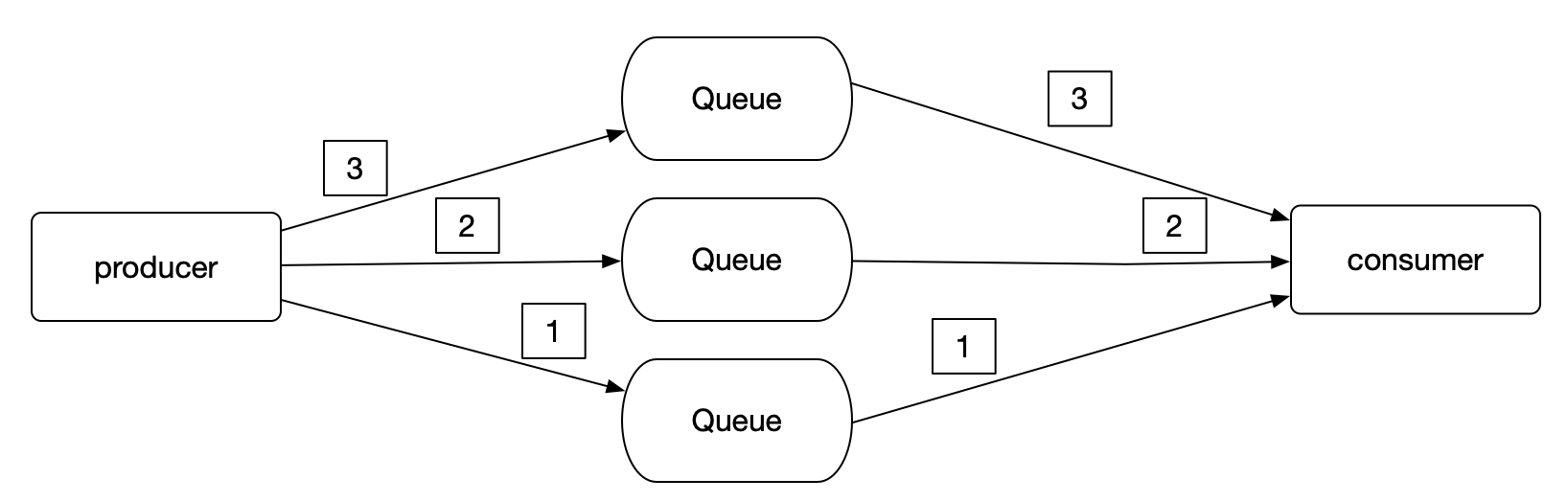
3.1.2. 单队列模型
单队列可以保证生产和消费有序
但此时消费者也需要单线程处理。如果多个消费者或多线程同时处理队列中的不同消息也会导致消费乱序。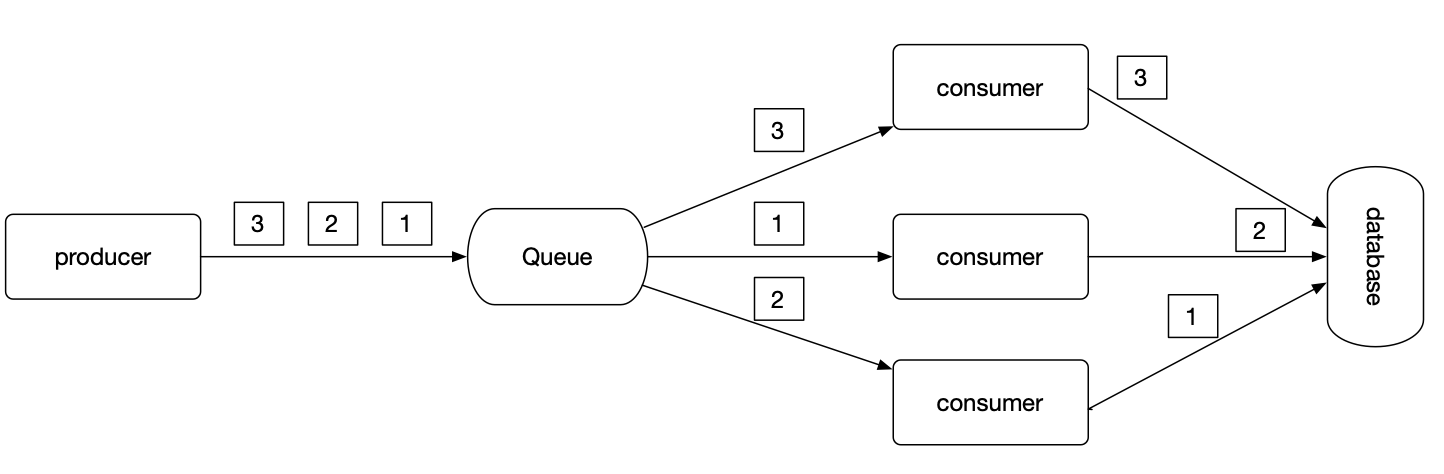
3.1.3. 局部保序
- 多队列可以提高生产和发送消息的效率,但无法保证全局有序。
- 单队列可以保证全局有序,但是性能较低
kafka属于典型的多队列模型,但是提供了一种局部保序的能力。kafka提供了分区partition key和consumer balance的机制来保证了一个topic下的某个partition里的消息可以被有序消费。
3.1.3.1. 生产有序
在发消息的时候指定Partition Key实现把某一类的消息都放入同一个Partition。例如云上project是资源隔离的最小单位,不同租户之间的资源处理的顺序并不会导致系统数据异常。我们可以使用project_id做key,这样同一个租户的消息肯定是在同一个partition中的,就保证了这个租户的的消息生产是有序的。
3.1.3.2. 消费有序
同时kafka的balance机制,保证了一个topic下面的某个partition只会被一个consumer group中的某一个consumer消费,因此保证了消费有序。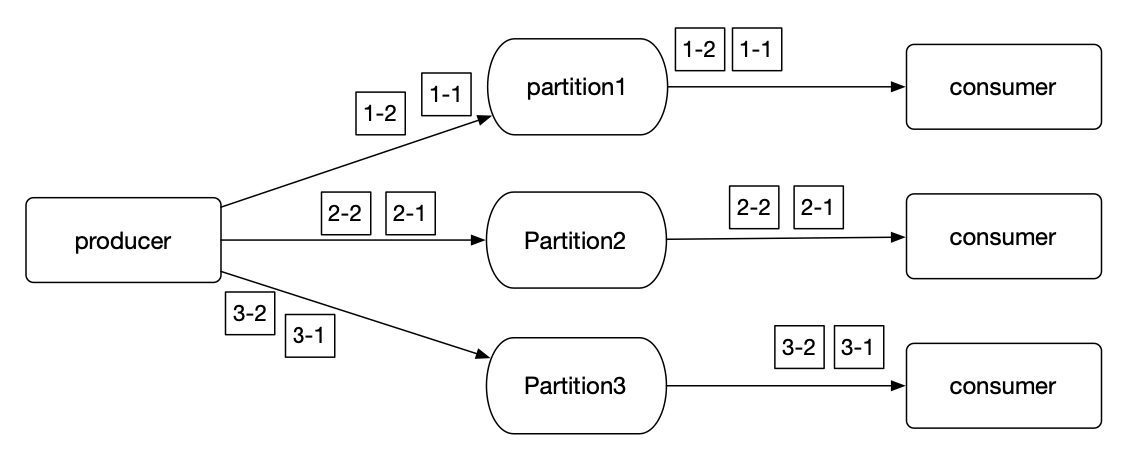
3.2. 消息推送模型
| 弱消费者 | 消息时延 | 顺序消息 | |
|---|---|---|---|
| push | 如果consumer的能力比producer的弱很多,势必造成消息在broker的堆积。broker需要考虑consumer的消息能力,如果broker给consumer推送一堆消息,consumer无法处理,导致broker压力剧增。 | push模型可以在消息到来的那一刻立刻推送给consumer,实现相对较低的时延 | 单partition只支持一个消费者消费,并且消费者只有确认一个消息消费后才能push送另外一个消息,还要发送者保证全局顺序唯一,成本太高了。尤其是必须每个消息消费确认后才能发下一条消息,这对于本身堆积能力和慢消费就是瓶颈的push模式的消息队列,简直是一场灾难。 |
| pull | consumer可以按需消费,不用担心消息过多处理不了。broker不用关心每个consumer的消费水平,设计相对简单,仅需维护好每个consumer的消费进度即可,甚至也可以完全让consumer自己维护。 | 这属于pull模式最大的短板,消费方无法准确地决定何时有消息达到,何时应该去拉消息。 | 实现简单 1. producer对应partition,并且单线程。 2. consumer对应partition,消费确认(或批量确认),继续消费即可 |
kafka采用long polling模型,可以一定程度上保证消息的及时性,其及时性主要受消费者消费速度的影响,如果消费者消息处理的非常快,那么就可以立即发起下一次poll,可以达到伪同步的效果。
3.3. 消息投递可靠性
- at most once: 消息可以丢,但是绝不会重复
- at least once: 消息不可以丢,但是可以重复
- exactly once: 消息不回丢,也不会重复
3.3.1. at most once
producer: 发送完之后,不管broker是否响应,都不会再进行重试(传输层协议UDP就是保证at most once)
consumer:pull或push消息后,不管consumer是否消费成功,offset都后移。
3.3.2. at least once
producer: 需要在网络出现超时重新发送相同的消息,也就是引入超时重试的机制,保证发出的每条消息都收到了broker确定的响应结果。
consumer: 消费端消费的每一条数据都通过ack机制进行确认
3.3.3. exactly once
考虑网络并不是完全可靠的,分布式系统想要实现理论上的exactly once是不可能的。
kafka提供的是at least once模型,但是可以通过幂等性(Idempotence)来一定程度实现这种语义。
3.3.3.1. 生产端幂等
kafka可以通过开启enable.idompotence配置项一键开启幂等能力,无需任何其他配置和额外代码编写。
- kafka会为每个producer在每个一个topic的每一个partition上生成一个三元组
(PID, TOPIC, Partition) - 以及对应的sequence号来唯一标识一条消息,和consumer端的offset类似,sequence号保证单调递增。
broker端会记录三元组和sequence号信息,broker会被收到的消息进行sequence号校验,如果检测到sequence号和已经记录的消息冲突,那么broker就会拒绝这次写入请求。 - kafka只能保证单会话上的幂等性,当producer重启后,就会被分配一个新的PID。
- kafka只能保证单分区的幂等性,因为produce在不同的partition上具有不同的三元组
(PID, TOPIC, Partition)。
3.3.3.2. 消费端幂等
- 将
enable.auto.commit设置为false - 在处理消息的时候,记录当前处理成功的每个消息的offset
- 当一批消息全部处理成功的时候通过
consumer.commitSync()手动提交;当一批消息部分处理成功通过seek(TopicPartition partition, long offset)方法来手动移动消费进度到最后一条处理成功的消息。如果消费端支持消息幂等处理的情况下,也可以都过nack的方式回滚当前批次的全部消息,对当前批次消息进行全部重试。
3.4. 事务能力
类似常见的数据库事务能力,消息队列的一致性用于保证多条消息要么全部成功,要么全部失败,kafka提供的事务默认默认是read committed级别。
Kafka事务「原理剖析」 - 昔久 - 博客园 (cnblogs.com)
两阶段提交原理 tcc原理(tcc)
3.4.1. producer
在producer端开启事务能力,需要满足以下两个条件
- 配置`enable.auto.commit=true
- 配置
transactional.id,可配置为主机uuid或hostname
在此基础上,服务端代码也需要按如下结构进行适配:
producer.initTransactions();
try {
producer.beginTransaction();
producer.send(record1);
producer.send(record2);
producer.commitTransaction();
} catch (KafkaException e) {
producer.abortTransaction();
}
3.4.2. consumer
开启事务后,producer在事务下部分消息写入失败,部分消息写入成功,Kafka实际上已经把这部分成功的数据写入到了底层的日志中,默认情况下consumer还是会看到这些消息。因此在consumer端,读取事务型producer发送的消息也需要进行一定程度的适配,通过设置isolation.level参数的值即可。当前这个参数有两个取值:
- read_uncommitted:这是默认值,表明consumer能够读取到任何写入kafka的消息,不论事务型producer提交事务还是终止事务。
- read_committed:表明consumer只会读取事务型producer成功提交事务写入的消息。
3.4.3. 数据库与kafka消息的一致性
3.4.3.1. 方案一
数据库事务中发送Kafka消息,性能差,且Kafka的故障会导致整体业务受损。最好做到异步。
3.4.3.2. 方案二
事务消息适用于异步更新的场景,对数据的实时性要求不高的地方,主要目的是为了解决消息生产者和消息消费者的数据一致性问题。使用消息队列MQ的时候,我们可以采用write ahead和write done的方式来保证事务的一致性。开启事务之前,先发送write ahead消息,告知消息消费者事务开启,随后生产者执行事务,并发送write done消息,如果write done消息发送成功,则可能保证消息消费者能够正确拿到消息,如果write done消息发送失败,则需要消息消费者根据ahead消息维护一个定时器,在超时后通过生产者提供的接口进行资源的反差,确认生产者的事务是否执行成功,并执行相应的消费或放弃操作。这里需要保证ahead消息中包括能够确认资源唯一性的键,通常使用资源主键替代。

评论